The PostgreSQL Performance Puzzle was, perhaps, too easy – it didn’t take long for someone to guess the correct answer!
But I didn’t see much discussion about why the difference or what was happening. My emphasis on the magnitude of the difference was a tip-off that there’s much more than meets the eye with this puzzle challenge – and one reason I published it is that I’d looked and I thought there were some very interesting things happening beneath the surface.
So let’s dig!
There are several layers. But – as with all SQL performance questions always – we begin simply with EXPLAIN.
[root@ip-172-31-36-129 ~]# sync; echo 1 > /proc/sys/vm/drop_caches
[root@ip-172-31-36-129 ~]# service postgresql-14 restart;
Redirecting to /bin/systemctl restart postgresql-14.service
pg-14.4 rw root@db1=# select 1;
...
The connection to the server was lost. Attempting reset: Succeeded.
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
pg-14.4 rw root@db1=# set track_io_timing=on;
SET
pg-14.4 rw root@db1=# set log_executor_stats=on;
SET
pg-14.4 rw root@db1=# set client_min_messages=log;
SET
pg-14.4 rw root@db1=# \timing on
Timing is on.
pg-14.4 rw root@db1=# explain (analyze,verbose,buffers,settings) select count(mydata) from test where mynumber1 < 500000;
LOG: 00000: EXECUTOR STATISTICS
DETAIL: ! system usage stats:
! 0.107946 s user, 0.028062 s system, 0.202054 s elapsed
! [0.113023 s user, 0.032292 s system total]
! 7728 kB max resident size
! 89984/0 [92376/360] filesystem blocks in/out
! 0/255 [1/1656] page faults/reclaims, 0 [0] swaps
! 0 [0] signals rcvd, 0/0 [0/0] messages rcvd/sent
! 197/0 [260/0] voluntary/involuntary context switches
LOCATION: ShowUsage, postgres.c:4898
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=20080.19..20080.20 rows=1 width=8) (actual time=190.273..190.278 rows=1 loops=1)
Output: count(mydata)
Buffers: shared hit=4 read=5533
I/O Timings: read=82.114
-> Index Scan using test_mynumber1 on public.test (cost=0.57..18803.24 rows=510781 width=18) (actual time=0.389..155.537 rows=499999 loops=1)
Output: mydata, mynumber1, mynumber2
Index Cond: (test.mynumber1 < 500000)
Buffers: shared hit=4 read=5533
I/O Timings: read=82.114
Settings: effective_cache_size = '8GB', max_parallel_workers_per_gather = '0'
Query Identifier: 970248584308223886
Planning:
Buffers: shared hit=58 read=29
I/O Timings: read=9.996
Planning Time: 10.529 ms
Execution Time: 190.819 ms
(16 rows)
Time: 213.768 ms
pg-14.4 rw root@db1=#That’s the EXPLAIN output for the first (ordered) column. It’s worth noting that even though the getrusage() data reported by log_executor_stats is gathered at a different level (by the operating system for the individual database PID), this data actually correlates very closely with the direct output of EXPLAIN ANALYZE on several dimensions:
- Explain reports
Execution Time: 190.819 msand getrusage() reports0.202054 s elapsed(very close) - Explain reports total
I/O Timings: read=82.114(subtracted from execution time, suggests 108.705 ms not doing I/O) and getrusage() reports0.107946 s user(very close, suggesting we didn’t spend time off CPU for anything other than I/O) - Explain reports
Buffers: shared ... read=5533(database blocks are 8k and filesystem blocks are 512 bytes, so this suggests 88528 filesystem blocks) and getrusage() reports89984/... filesystem blocks in/...(again very close) - Average latency of a PostgreSQL read request (based on EXPLAIN): 82.114 ms / 5533 blocks = 0.0148 ms
On a side note… this is one reason I appreciate that PostgreSQL uses a per-process model rather than the threaded model of MySQL. There are other advantages with the threaded model – but as far as I’m aware, operating systems don’t track resource usage data per thread.
Repeating the same steps with the second (random) column:
pg-14.4 rw root@db1=# explain (analyze,verbose,buffers,settings) select count(mydata) from test where mynumber2 < 500000;
LOG: 00000: EXECUTOR STATISTICS
DETAIL: ! system usage stats:
! 1.117137 s user, 3.740477 s system, 117.880721 s elapsed
! [1.124219 s user, 3.742426 s system total]
! 7716 kB max resident size
! 11550752/0 [11553144/360] filesystem blocks in/out
! 0/1710 [1/3112] page faults/reclaims, 0 [0] swaps
! 0 [0] signals rcvd, 0/0 [0/0] messages rcvd/sent
! 254529/2 [254593/2] voluntary/involuntary context switches
LOCATION: ShowUsage, postgres.c:4898
LOG: 00000: duration: 117891.942 ms statement: explain (analyze,verbose,buffers,settings) select count(mydata) from test where mynumber2 < 500000;
LOCATION: exec_simple_query, postgres.c:1306
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=1608908.23..1608908.24 rows=1 width=8) (actual time=117869.626..117869.633 rows=1 loops=1)
Output: count(mydata)
Buffers: shared hit=123528 read=378035
I/O Timings: read=116996.143
-> Index Scan using test_mynumber2 on public.test (cost=0.57..1607599.58 rows=523462 width=18) (actual time=0.417..117799.607 rows=500360 loops=1)
Output: mydata, mynumber1, mynumber2
Index Cond: (test.mynumber2 < 500000)
Buffers: shared hit=123528 read=378035
I/O Timings: read=116996.143
Settings: effective_cache_size = '8GB', max_parallel_workers_per_gather = '0'
Query Identifier: 6487474355041514631
Planning:
Buffers: shared hit=58 read=29
I/O Timings: read=9.137
Planning Time: 9.673 ms
Execution Time: 117870.258 ms
(16 rows)
Time: 117892.603 ms (01:57.893)
pg-14.4 rw root@db1=#Again, we see that the execution time and I/O timings are very close between getrusage() and EXPLAIN output. It takes over 100 seconds, which I mentioned in my previous article.
And immediately, a huge difference jumps out: the number of blocks being read.
Our first query only needed to read 5,533 database blocks to find the 500,000 rows it was looking for. But – in the same table – this second query needs to read 378,035 blocks to find the 500,000 rows it’s looking for!
This, of course, is simply due to the way the data is physically laid out on the disk – which is a product of the query we used to populate the table. Note that in PostgreSQL, a whole new row is created every time you update even a single byte, so you generally won’t see neat and clean sequential data like this on real-world production systems.
I’d be remiss right now if I didn’t mention great articles already written by other people on this topic. Two come to mind right away. Two years ago, Ryan Lambert at RustProof Labs wrote an article about almost exactly the test case I’ve reproduced here. His table also has one text column and two numeric columns, populated with ordered and non-ordered data. Ryan’s article does a great job of walking through the fundamentals on this. And just last week, Michael Christofides at pgMustard wrote an excellent technical article about the importance of the BUFFERS metric when studying query performance. I think it’s spot on and well worded, and I pretty much agree with the whole article. I certainly agree that it would be great if BUFFERS were enabled by default for EXPLAIN output in a future version of PostgreSQL.
Side Note: PostgreSQL Optimization on Repeat Buffer Visits
Grant me one brief digression for a moment. Speaking of BUFFERS, there’s a glaring inconsistency in the two explain plans above. The second (random) query shows 123,528 shared hits and 378,035 shared reads. That adds up to 501,563 buffer accesses and this makes perfect sense for 500,000 rows.
But the first (ordered) query shows only 5,537 buffers in total. At first, I was a little surprised to see “shared hit” was not incremented when buffers were re-visited for multiple rows. The obvious explanation seemed to be a PostgreSQL optimization when doing an index range scan and accessing same block repeatedly for multiple tuples.
I did a little searching and found that this is exactly the case. It’s an optimization that applies to “heap” type relations when they are accessed through an index. More specifically, the heapam_index_getch_tuple() function uses the ReleaseAndReadBuffer() call to switch buffers. That call has the optimization to check if the block being requested is the same one being released, and saves considerable work by short-circuiting much code that normally needs to be called. This is part of the “why” behind Ryan Lambert’s observation (which I also corroborated) that even for fully cached queries accessing the same number of blocks, sequential access patterns are faster – using less CPU – than random access patterns.
Comparing with Equal Number of Blocks
So we expect a little less time on CPU for sequential access patterns, but of course my test here is designed to spend most of the time in I/O. So in the interest of research, let’s reduce the number of rows in the second query so that it accesses roughly the same number of blocks as the first one. I’m curious what we’ll see.
Note that when I reduced the number of rows to 5400, PostgreSQL switched to a bitmap heap scan. In the interest of a more apples-to-apples comparison, I’m going to disable bitmap scans so that PostgreSQL stays with the index range scan.
pg-14.4 rw root@db1=# set enable_bitmapscan=off;
SET
pg-14.4 rw root@db1=# explain (analyze,verbose,buffers,settings) select count(mydata) from test where mynumber2 < 5400;
LOG: 00000: EXECUTOR STATISTICS
DETAIL: ! system usage stats:
! 0.020220 s user, 0.056453 s system, 2.208467 s elapsed
! [0.030746 s user, 0.060501 s system total]
! 7712 kB max resident size
! 92352/0 [94744/360] filesystem blocks in/out
! 0/254 [1/1657] page faults/reclaims, 0 [0] swaps
! 0 [0] signals rcvd, 0/0 [0/0] messages rcvd/sent
! 5489/0 [5553/0] voluntary/involuntary context switches
LOCATION: ShowUsage, postgres.c:4898
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=22701.59..22701.60 rows=1 width=8) (actual time=2197.749..2197.755 rows=1 loops=1)
Output: count(mydata)
Buffers: shared hit=19 read=5477
I/O Timings: read=2185.404
-> Index Scan using test_mynumber2 on public.test (cost=0.57..22687.46 rows=5652 width=18) (actual time=0.446..2196.772 rows=5479 loops=1)
Output: mydata, mynumber1, mynumber2
Index Cond: (test.mynumber2 < 5400)
Buffers: shared hit=19 read=5477
I/O Timings: read=2185.404
Settings: effective_cache_size = '8GB', enable_bitmapscan = 'off', max_parallel_workers_per_gather = '0'
Query Identifier: 6487474355041514631
Planning:
Buffers: shared hit=58 read=29
I/O Timings: read=9.359
Planning Time: 9.892 ms
Execution Time: 2197.851 ms
(16 rows)
Time: 2220.479 ms (00:02.220)
pg-14.4 rw root@db1=#Now that is interesting!
The getrusage() CPU numbers are very close, and the operating system (512 byte) block count is pretty close to the database block read count of 5477. But look at the time! We’re reading 5,477 blocks in 2,185 ms which means the average latency of a PostgreSQL read request is 0.4 ms.
Now let me be honest. I find 0.4 ms read latency from a GP2 volume to be a completely reasonable number. On the other hand, our first (sequential) query reported a PostgreSQL read request latency of 0.0148 ms. I don’t believe that for a second. POSTRESQL I’M CALLING YOUR BLUFF, YOU LIAR.
How do I call the bluff? Easy, just take a quick look at iostat output while we run the query on my otherwise idle test system.
First, lets get the numbers for the random access pattern to make sure they check out.
pg-14.4 rw root@db1=# explain (analyze,verbose,buffers,settings) select count(mydata) from test where mynumber2 < 5400;
[root@ip-172-31-36-129 ~]# iostat -x 4
avg-cpu: %user %nice %system %iowait %steal %idle
2.63 0.00 7.51 23.53 0.00 66.33
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
nvme0n1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
nvme1n1 0.00 0.00 1383.75 0.00 11644.00 0.00 16.83 0.48 0.34 0.34 0.00 0.36 49.52That was the second (random) query. The iostat numbers are per-second, so multiplying by 4 (seconds) I see that iostat reports a total of 5535 read requests (r/s=1383.75) and await is 0.34 ms. Above, PostgreSQL EXPLAIN claimed 5,477 database blocks at 0.4 ms average read latency. Survey says… PostgreSQL is telling the truth!
pg-14.4 rw root@db1=# explain (analyze,verbose,buffers,settings) select count(mydata) from test where mynumber1 < 500000;
[root@ip-172-31-36-129 ~]# iostat -x 4
avg-cpu: %user %nice %system %iowait %steal %idle
1.38 0.00 0.38 0.88 0.00 97.38
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
nvme0n1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
nvme1n1 0.00 3.50 104.75 0.50 11344.00 16.00 215.87 0.08 0.80 0.80 1.50 0.51 5.38Now this was the first (sequential) query. The iostat numbers show await of 0.8000 ms. Above, PostgreSQL EXPLAIN claimed 0.0148 ms average read latency – not even remotely close.
There you have it, PostgreSQL clearly LIED to us!
But there’s something interesting here. I see that r/s=104.75 in the iostat output. Multiplying by 4, why only 419 reads? The total rkB for all 4 seconds would be 45376 (11344 times 4) which translates to 5672 database blocks at 8k each (45376 divided by 8), so that seems right – but the number of I/O read requests reported by iostat is strangely small.
What’s going on here?
In fact, Frits Hoogland nailed it on the head when I first posted this performance puzzle on Twitter:
Linux Readahead

Of course, PostgreSQL isn’t actually lying. It is telling the truth from its perspective, but PostgreSQL reads are not the same thing as physical device reads. There is an operating system in the middle – Linux – which does an awful lot more than many people realize. Linux maintains its own “page” cache and applies its own optimizations to reads and writes in the I/O path. (I made a simple sketch of this architecture for the 2019 article about PostgreSQL invalid pages.) One of those optimizations is called readahead.
My favorite technical write-up that I’ve found so far about Linux readahead is the article that Neil Brown contributed to LWN.net just three months ago. I think PostgreSQL developers will especially appreciate this author’s take, with his emphasis on the importance in the code of clear concepts, language & naming and his emphasis on the value of documentation-writing that’s intertwined and integrated with code-writing.
A core idea in readahead is to take a risk and read more than was requested. If that risk brings rewards and the extra data is accessed, then that justifies a further risk of reading even more data that hasn’t been requested.
Neil Brown
Linux readahead is a heuristic process. The operating system does not have any direct visibility into which blocks PostgreSQL will request in the future (whereas the database itself could know this, for example looking ahead in the index to know heap blocks that will later be requested), but Linux has an algorithm to make guesses and factor in the success rate for future guessing. I’m only going to scratch the surface of interactions between PostgreSQL and the Linux readahead algorithm, but there is still a surprise or two (for me) herein.
As a starting point, I’ll use a couple very simple techniques to look at readahead behavior with individual PostgreSQL queries on my dedicated & idle test system:
- Generate histograms of read request sizes at the operating system level with
blktrace | blkiomon - Generate histograms at the PostgreSQL level with Bertrand Drouvot’s BCC-based
pg_ebpfscript (plus a few tweaks I made) - Use
blockdevto set the readahead value to zero and compare that behavior with the default value of 256.
Note: Andres Freund also has published a few eBPF scripts for PostgreSQL, including one that directly reports pagecache hits – but they rely on bpftrace which isn’t yet available in the standad yum repositories for RHEL7, as far as I can tell at the moment. I started with Bertrand’s script simply because I’m lazy and BCC was available from the standard yum repos… but I do want to look closer at Andres’ scripts too.
Linux Readahead Histograms
Bertrand’s script will take any function in the PostgreSQL code base as an input, and for that function it will track every single call, and how long the function takes to run. It will then generate a histogram visualizing the data. I’m going to tap into the PostgreSQL function FileRead which, in this case, captures all of the block reads that I’m interested in. One of my tweaks adds an option to NOT zero the call counts between display updates (a la perf-top), which is convenient for this particular test.
[root@ip-172-31-36-129 pg_ebpf]# ./get_pg_calls_durations.py -i 2 -f FileRead -x /usr/pgsql-14/bin/postgres -p 2033 -nI don’t have an option with blkiomon to avoid resetting call counts between display updates, so I’m going to set an update frequency a little over my known query runtime and run the query right after an update, so that I can get a single display with all the information about the query. (And I’ll make sure the next display has all zeros.) Four second refresh rate should do the trick.
[root@ip-172-31-36-129 ~]# blktrace /dev/nvme1n1 -a issue -a complete -o- | blkiomon -I 4 -h -Let’s take a look at the first (sequential) query:

A few observations from the block device stats (on the right):
- The “d2c” histogram shows only 3 reads in the 128-256 microsecond bucket, and the vast majority of reads seem to complete around a half millisecond (either 256-512 microseconds or 512-1024 microseconds). None were less than 128 microseconds.
- There are 347 read requests issued by Linux at a size of 128k which matches the default readahead setting of 256 sectors (a sector is 512 bytes). Contrast that with only 38 read requests for 8k (DB block size) and 66 read requests for 4k (OS page size).
- In the “sizes read (bytes)” summary line, we see sum=46718976 bytes, which very closely matches the total rKB that we saw from iostat earlier of 45376 kB.
- In the “d2c read (usec)” summary line, we see avg=787.1 microseconds, which very closely matches the await time that we saw from iostat earlier of 0.80 ms.
- Both summary lines show num=484 which is close to the 419 I/O requests we saw from iostat in the earlier test.
A few observations from the eBPF histogram (on the left):
- The total for the top (count) histogram means that the FileRead() function was called 5,599 times. This is very close to the 5,533 “shared read” statistic in the EXPLAIN output.
- The total for the bottom (time) histogram means all executions of the FileRead() function ran for a cumulative total of 119,134 microseconds. This invocation reported
I/O Timings: read=108.129in the EXPLAIN output. These numbers are very close. (The original run at the beginning of this article reported 82.114 ms.) - The top histogram shows that exactly 152 calls to FileRead() completed in more than 256 microseconds, whereas 5447 calls to FileRead() completed in less than 256 microseconds.
When you think about it, it’s amazing how fast this happens. This query starts with a cold pagecache and completes in one tenth of a second. And yet, in the flash of an eye, Linux figures out what’s happening and in the background it asynchronously pre-populates its page cache with 98% of the data that PostreSQL asks for – before PosgreSQL asks for it. We see more than 5000 reads that PostgreSQL issues (to an ostensibly “cold” page cache), served back in single-digit microseconds.
The other thing that amazes me: the tiny percentage (2%) of reads that seem to require physical OS reads (over 256 microseconds) – they account for a cumulative total of 68974 microseconds – that’s 58% of the execution time.
Just imagine how slow this would be without readahead!
Linux Readahead Disabled
Actually, scratch that, instead of imagining it lets just try it. (And it’s not as bad as I made it sound.) 🙂
[root@ip-172-31-36-129 pg_ebpf]# blockdev --report /dev/nvme1n1
RO RA SSZ BSZ StartSec Size Device
rw 256 512 4096 0 107374182400 /dev/nvme1n1
[root@ip-172-31-36-129 pg_ebpf]# blockdev --setra 0 /dev/nvme1n1
[root@ip-172-31-36-129 pg_ebpf]# blockdev --report /dev/nvme1n1
RO RA SSZ BSZ StartSec Size Device
rw 0 512 4096 0 107374182400 /dev/nvme1n1
[root@ip-172-31-36-129 pg_ebpf]#Gathering the same histograms:
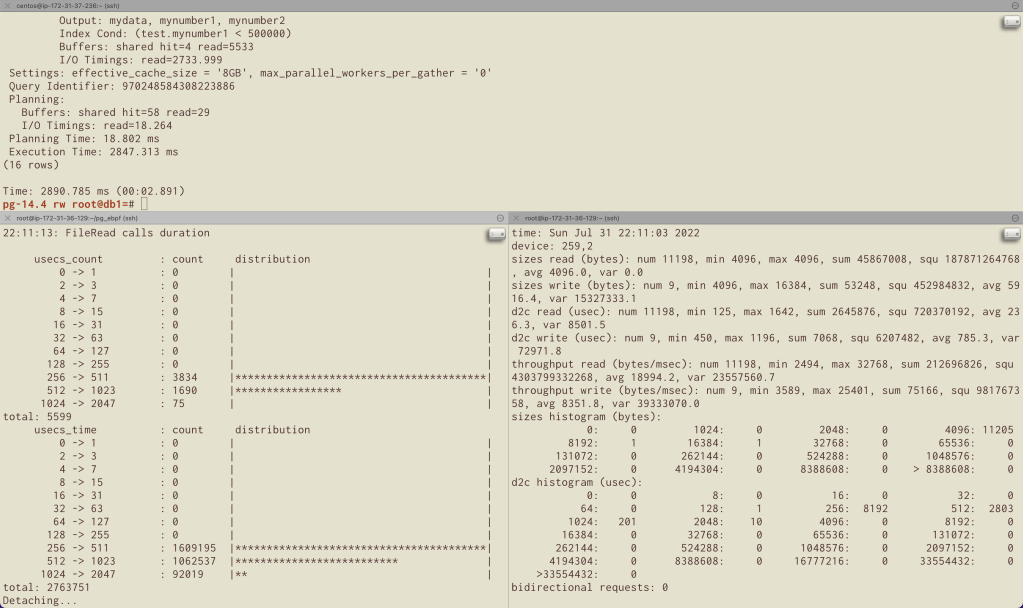
Overall execution time of 2847 ms – which is close to the execution time for our query that ran with randomly ordered data! (Not surprising since it did the same amount of I/O, presumably without benefiting from readahead.)
Furthermore:
- Nearly all block-device I/O requests are made at the OS page size of 4k
- At both the block device and PostgreSQL layers, the majority of I/O requests are completing in less than a half millisecond. Interestingly, from Linux’s perspective this GP2 volume seemed to serve most requests in less than a quarter millisecond for this test – and it claims one (likely 4k page) request was served in less than 128 microseconds! (Dang.)
- The PostgreSQL histogram shows that not a single 8k block I/O completed in less than 256 microseconds, which corroborates our interpretation of the earlier histogram involving readahead.
The summary lines from blkiomon both show a total of 11,198 I/O requests. Of course these are 4k OS pages, and that number is double the number of read() calls that PostgreSQL is making to the operating system.
And this is the first thing that surprised me. This means that on all workloads – including completely random patterns – something related to Linux readahead code is what’s preserving 8k-at-a-time reads.
Linux Readahead Wastefulness and Dumb Luck
So clearly, Linux readahead code isn’t just a “nice-to-have” but rather it’s integral to an efficient I/O path with any PostgreSQL workload.
But there’s another thing that I thought was surprising.
You may not have noticed, but I glossed over one little detail back in the EXPLAIN output of the original query with a random data layout. I quietly left out any comments about the getrusage() reported filesystem block reads. I explicitly called this out on the sequential query. Go back up and look again… I’m sneaky, right?
pg-14.4 rw root@db1=# explain (analyze,verbose,buffers,settings) select count(mydata) from test where mynumber2 < 500000;
...
...
! 11550752/0 [11553144/360] filesystem blocks in/out
...
...
Buffers: shared hit=123528 read=378035Explain reports Buffers: shared ... read=378036 (database blocks are 8k and filesystem blocks are 512 bytes, so this suggests 6048576 filesystem blocks) and getrusage() reports 11553144/... filesystem blocks in/...
That is NOT close. In fact, getrusage() is telling us the operating system reads almost DOUBLE the amount of data being returned to PosgreSQL.
Now that was a surprise to me, since this is a completely random read pattern for the bulk of the I/O requests going to the table/heap.
Lets take a look at the histograms. (It kills me to wait… but I’ll increase the blkiomon interval to 150!)

Observations:
- PostgreSQL histogram reports total time of 111897181 microseconds in FileRead() function, which is close to the SQL execution time of 113585 ms.
- PostgreSQL histogram reports total 378,060 calls to FileRead() and the summary line in
blkiomonshows num=355373 (I/O requests) which is close. - There were more than 100,000 block device read requests in the 16k, 32k, 64k, 128k and 256k buckets. (Readahead doing more than 8k.)
- The summary line “sizes read(bytes)” shows sum=5914181632 which corroborates the earlier
iostatnumbers (divided by 512, that would be 11551136 filesystem blocks). - The 378,060 blocks (8k each) that PostgreSQL read = a total of 3097067520 bytes.
So it appears that – yes – Linux readahead is wastefully reading almost double the amount of data into the page cache, and almost half of that data is not returned to PosgreSQL.
We also see that the SQL command “SET log_executor_stats” can be used in PostgreSQL to infer [with getrusage() data] if Linux readahead happens to be badly polluting your OS page cache. 🙂
But here’s what surprised me the most: look at the PostgreSQL eBPF histogram. On this random workload, one third of PostgreSQL FileRead() calls [123,070 out of total 378,060] completed in single or double-digit microsecond time, indicating pagecache hits due to readahead.

And if you think that’s a lot… with a minor tweak of the way I populate this table, I saw Linux readahead serve almost 90% of random reads from page cache, starting cold!! (New puzzle… I challenge you to reproduce that! Click the thumbnail for a screenshot!)
Talk about dumb luck.
I don’t care what anyone else says about you, Linux Readahead. Next time I go to Vegas, I’m taking you with me, friend.




Discussion
Trackbacks/Pingbacks
Pingback: Researching the Performance Puzzle | Ardent Performance Computing – Radu Pârvu's Site - August 6, 2022