There are four major components to being a good benchmark engineer:
- Methodology: A good benchmark engineer defines the goals and non-goals of the exercise, makes strong choices on variables in the experiment, configures the SUT in a valid manner, and makes smart decisions about when and how to iterate the test.
- Investigation: A good benchmark engineer asks “why” about the results of a test, taking initiative themself to dive deep into system behavior and question unproven assumptions.
- Explainability: A good benchmark engineer documents their findings with enough information for another engineer to reproduce the test and the results, directly sharing scripts and configuration as far as possible, and clearly explains the results & the causes & the significance of the performance test.
- Accountability: A good benchmark engineer publishes their performance test results and they thoughtfully and humbly engage with critics of the results in good faith, clarifying and updating and defending and iterating if needed, aiming to achieve as much consensus as possible.
Apparently it’s benchmark week in the Postgres world. I only have two data points but that’s enough for me!
First data point:
I’m visiting Portland. This Thursday Aug 22, the Portland Postgres Users Group (PDXPUG) is having a meetup where Paul Jungwirth is going to be talking about postgres benchmarking in general and walking though CMU’s Benchbase tool. I’ve spent a fair bit of time around Postgres performance testing myself, including Benchbase. I also have a few database friends around the Portland area. So at the last minute, I decided to drive down to Portland for the meetup this week and catch up with friends. It sounds like Mark Wong might be able to make it to the meetup (he’s also a very long time postgres benchmarking person) …and I’ve pinged some other folks with benchmarking and performance experience to see if we make it a real benchmark party.
It should be fun! If you’re around Portland, come join us! Especially if you have any interest in performance testing!
Edit: the meetup went great! Here’s what I posted on LinkedIn:
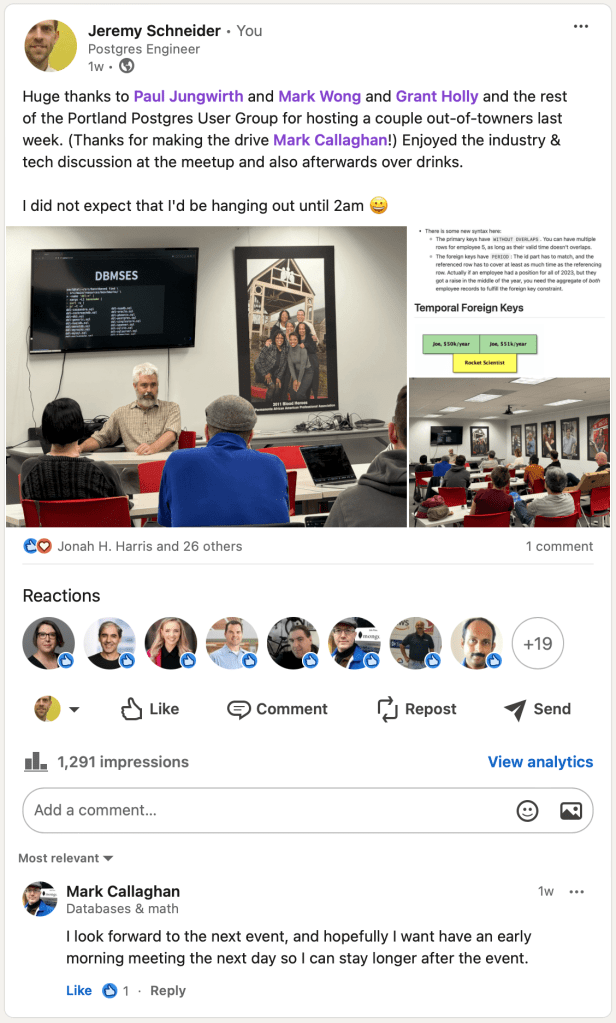
Second data point:
All this was in the back of my mind when Michael and Nikolay dropped their latest postgres.fm podcast episode two days ago. With over a hundred quality episodes, I keep expecting them to run out of ideas any day now. And there is no indication they are anywhere close to running out of ideas yet.
This weekend I was surprised and delighted. They got Melanie Plageman for an interview – a dynamic and sharp Postgres contributor who became a committer this year, and who I think does a superb job explaining complex topics in a clear and accessible way.
Best of all: the topic for this podcast is “getting started with benchmarking” 😀

…
I listened through the whole podcast and it’s great. Worth listening.
My intro to this blog – four major components to being a good benchmark engineer – are all based on topics that Melanie discusses and examples that she gives.
To encourage you to come to our Portland Benchmark Party and continue the conversation (if you’re around Portland), I thought I’d type up and share my notes & thoughts from listening to this postgres.fm podcast with Melanie.
First thing Melanie says to open the podcast, is to talk about the value of mentorship and having opportunities when you’re early in your career to learn from others:
“I’ve gotten to talk to and learn from people that know how to do it … at microsoft and in the community … but not everyone gets to learn from people that have 15 and 20 years of experience … so i like talking about it and seeing if i can help people get started and demystify what i can”
Jeremy: There are many ways this happens! In the 2000’s, I learned from experienced engineers through blogs and email lists and local user groups. One new development specific to Postgres: Robert Haas recently kicked off a postgres community mentorship program to connect newer postgres contributors with experienced members of the community. (announcement) (update)
Melanie tells the story of an early experience doing performance testing. She was working with a senior Postgres community member, and her patch should have shown improvement but her test was not giving expected results. After looking at how she configured (or rather didn’t configure) Postgres before running the performance test… “he was like, ok well just throw all of this away” 😂 … I admit that I laughed out loud at this. I can relate! I’ve had to throw everything away and start over more than once! It’s all part of how we become better engineers.
15:35 – Michael asks for a few examples of specific people doing Postgres performance work. There are a few nice shout-outs here. First person Melanie mentioned that she follows is Mark Callaghan, and he might be the first person I’d have mentioned too. Also we all got to meet him at pgconf.dev in Vancouver this year which was great! (Thanks for coming Mark!) Nikolay specifically mentioned liking the pun in Mark’s blog name (small datum 😂❤️). In addition to Mark, there were shout-outs to Tomas Vondra, Andres Freund, Alexander Lakhin and Mark Wong. And of course this is not everyone but I think it’s great to give some credit to these folks!
Besides all the experience he has, Melanie described a few things that Mark Callaghan really exemplifies: (1) describing the methodology, which Mark does in great detail (2) diversity of workloads – for example small and large servers (3) doublecheck every result and investigate every discrepancy (4) publish it and be accountable for it.
Number 4 especially: People will come after you and you have to be ready to defend your work! It’s almost like a full time job in itself.
There’s ongoing work around a Postgres performance farm initiative but it’s really hard to agree on what is a useful benchmark in general to run.
You can’t just say “I set up this farm and I ran all these benchmarks and now I expect other people to go look at them”. As a benchmarker you’re accountable for the analysis and trying to find out if the results are valid.
23:30 – Melanie is talking about all the metrics she gathers (many dozens), and giving a specific example around a vacuum-related patch she’s working on now, and she mentions how she uses wait events to see what autovacuum workers are doing.
Jeremy: Readers know that I’m a big proponent of wait events as the entry point to performance analysis, so of course I have to highlight this comment from Melanie. 🙂
27:40 – Melanie had said she often uses per-transaction logging (-l flag) with pgbench. Nikolay digs into how this is possible without overhead significantly skewing the test results. Great tip here – Melanie has pgbench output go to tmpfs and copies the data to persistent storage after the benchmark is finished. (This can work as long as the amount of data doesn’t completely overwhelm available memory – might not work for long running benchmarks with many clients/jobs.)
Next Melanie tells the story of the pg_stat_io patch, which was a much acclaimed new feature in Postgres 16 that Melanie authored.
I love stories and this is a great one. It turns out that there’s some interesting history here.
When Melanie first started working on the patch, it was a lot bigger and more complicated because of the way the stats collector worked. In fact she eventually had to shelve it and do some other work. But she used the patch privately when doing some async-IO related work, and she found it useful to have extra stats on the IO path during her development work.
Some time later, Kyotaro Horiguchi submitted a set of patches to refactor the whole stats system to use shared memory instead of inter-process communication. Andres Freund worked with Kyotaro on this patchset for some time, and Melanie also had the opportunity to be involved in this patch. This was committed and shipped for Postgres 15. (BTW, this is an under-appreciated significant under-the-hood update in v15!)
But having been involved in the stats patch, Melanie realized that with the new framework her pg_stat_io patch could now be much smaller and simpler. So she went back to it and after some work it was committed for v16.
To Melanie, as a postgres developer, the value was most evident to her in development work. But Nikolay and Michael conveyed how much we users appreciated this patch – I strongly concur!
Jeremy: It’s not coincidental that “Observability” was a huge topic at pgconf.dev in Vancouver, and that a bunch of people put their emails on a list asking us to start a Postgres Observability Special Interest Group – I hope to help with some follow-up later this fall.
But the big moral here is how patches work with Postgres community. If you are a database developer with a good idea, it might not get buy-in right away but don’t get too discouraged and it’s good to keep your ideas on the shelf and come back to them periodically!
35:40 – Michael asks: “how do you choose which things to benchmark and which things not to benchmark?”
Melanie gave a fantastic and detailed discussion/explanation around this, starting with the very beginning of her professional software engineering career and how she developed intuition around this. This was my favorite part of the podcast. I’m not going to summarize – give it a listen!
40:30 – Nikolay asks: “I’m curious what you’re working on right now”
Melanie: “I wanted to take a break from vacuum this release but it didn’t work out that way”
LOL 😂 I laughed out loud again. I can relate, sometimes you start something or do some good work… and then it continues to follow you (for me, collation).
48:15 – Melanie gives a shout-out to Masahiko Sawada’s vacuum improvement that’s in Postgres 17 which I’m also very excited about. I think it might be one of the most important new features in v17. Michael and Nikolay asked if she can explain a bit more, and Melanie gave a fantastic technical walk-through of the feature.
Jeremy: during the discussion about ongoing work, I was happy to hear about active discussions and work toward global indexes and toward autovacuum scheduling improvements.
Michael then sums up my thoughts perfectly: “I like this kind of work. Things that will help people – almost everybody will benefit without having to change anything. Those are so powerful, and so easily forgotten or so easily ignored, but everybody benefits. Almost everybody without (A) noticing and (B) having to do anything. Those kinds of changes are so powerful.”
Melanie: “the dream is that we get rid of all those autovacuum GUCs”
Nikolay, quietly freaking out: “wow. this is a radical position.” 😂 I laughed out loud, yet again, completely relate.
Melanie: “it’s not going to happen overnight” (implied: don’t freak out, Jeremy!)
And that wraps it up.
So now, go listen to the podcast for yourself!
And come join our benchmark party this Thursday in Portland.
.
Links referenced in this blog:
- https://pdxpug.wordpress.com/2024/08/07/pdxpug-august-22nd-benchmarking-with-benchbase/
- https://github.com/cmu-db/benchbase
- https://postgres.fm/episodes/getting-started-with-benchmarking
- https://rhaas.blogspot.com/2024/06/mentoring-program-for-code-contributors.html
- https://rhaas.blogspot.com/2024/07/mentoring-program-updates.html
- https://www.percona.com/blog/postgresql-15-stats-collector-gone-whats-new/
- https://pganalyze.com/blog/pg-stat-io
- https://pganalyze.com/blog/5mins-postgres-17-faster-vacuum-adaptive-radix-trees




Discussion
No comments yet.