This article is a shortened version. For the full writeup, go to https://github.com/ardentperf/pg-idle-test/tree/main/conn_exhaustion
This test suite demonstrates a failure mode when application bugs which poison connection pools collide with PgBouncers that are missing peer config and positioned behind a load balancer. PgBouncer’s peering feature (added with v1.19 in 2023) should be configured if multiple PgBouncers are being used with a load balancer – this feature prevents the escalation demonstrated here.
The failures described here are based on real-world experiences. While uncommon, this failure mode has been seen multiple times in the field.
Along the way, we discover unexpected behaviors (bugs?) in Go’s database/sql (or sqlx) connection pooler with the pgx client and in Postgres itself.
Sample output: https://github.com/ardentperf/pg-idle-test/actions/workflows/test.yml
The Problem in Brief
Go’s database/sql allows connection pools to become poisoned by returning connections with open transactions for re-use. Transactions opened with db.BeginTx() will be cleaned up, but – for example – conn.ExecContext(..., "BEGIN") will not be cleaned up. PR #2481 adds some cleanup logic in pgx for database/sql connection pools; I tested the PR with this test suite. The PR relies on the TxStatus indicator in the ReadyForStatus message which Postgres sends back to the client as part of its network protocol.
A poisoned connection pool can cause an application brownout since other sessions updating the same row wait indefinitely for the blocking transaction to commit or rollback its own update. On a high-activity or critical table, this can quickly lead to significant pile-ups of connections waiting to update the same locked row. With Go this means context deadline timeouts and retries and connection thrashing by all of the threads and processes that are trying to update the row. Backoff logic is often lacking in these code paths. When there is a currently running SQL (hung – waiting for a lock), pgx first tries to send a cancel request and then will proceed to a hard socket close.
If PgBouncer’s peering feature is not enabled, then cancel requests load-balanced across multiple PgBouncers will fail because the cancel key only exists on the PgBouncer that created the original connection. The peering feature solves the cancel routing problem by allowing PgBouncers to forward cancel requests to the correct peer that holds the cancel key. This feature should be enabled – the test suite demonstrates what happens when it is not.
Postgres immediately cleans up connections when it receives a cancel request. However, by default Postgres does not clean up connections when their TCP sockets are hard closed, if the connection is waiting for a lock. As a result, Postgres connection usage climbs while PgBouncer continually opens new connections that block on the same row. The app’s poisoned connection pool quickly leads to complete connection exhaustion in the Postgres server.
Edit Feb 5: Postgres setting client_connection_check_interval enables dead connection cleanup.
Existing connections will continue to work, as long as they don’t try to update the row which is locked. But the row-level brownout now becomes a database-level brownout – or perhaps a complete system outage (once the Go database/sql connection pool is exhausted) – because postgres rejects all new connection attempts from the application.
Result: Failed cancels → client closes socket → backends keep running → CLOSE_WAIT accumulates → Postgres hits max_connections → system outage
Table of Contents
- The Problem in Brief
- Table of Contents
- Architecture
- The Test Scenarios
- Test Results
- Detection and Prevention
Architecture
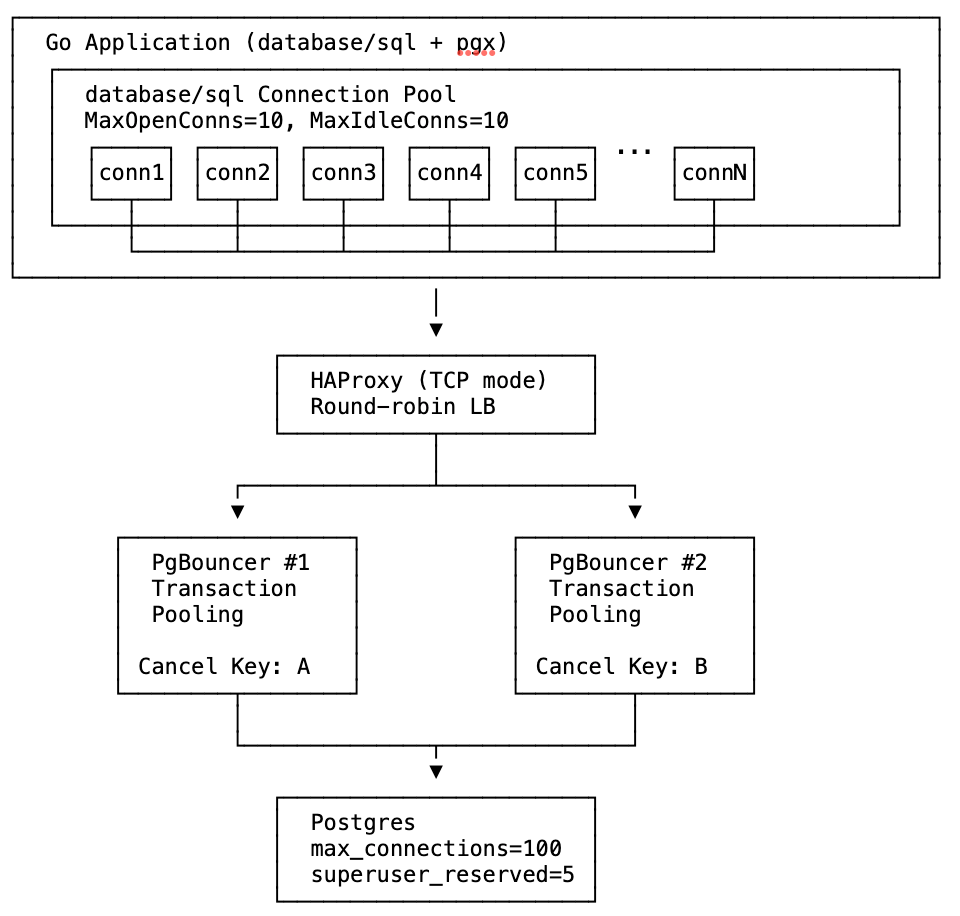
The test uses Docker Compose to create this infrastructure with configurable number of PgBouncer instances.
The Test Scenarios
test_poisoned_connpool_exhaustion.sh accepts three parameters: <num_pgbouncers> <poison|sleep> <peers|nopeers>
In this test suite:
- The failure is injected 20 seconds after the test starts.
- Idle connections are aborted and rolled back after 20 seconds.
- Postgres is configured to abort and rollback any and all transactions if they are not completed within 40 seconds. Note that the
transaction_timeoutsetting (for total transaction time) should be used cautiously, and is available in Postgres v17 and newer.
PgBouncer Count: 1 vs 2 (nopeers mode)
| Config | Cancel Behavior | Outcome |
|---|---|---|
| 1 PgBouncer | All cancels route to same instance | Cancels succeed, no connection exhaustion |
| 2 PgBouncers | ~50% cancels route to wrong instance | Cancels fail, connection exhaustion |
Failure Mode: Sleep vs Poison
| Mode | What Happens | Outcome | Timeout |
|---|---|---|---|
| sleep | Transaction with row lock is held for 40 seconds without returning to pool | Normal blocking scenario where lock holder is idle (not sending queries) | Idle timeout fires after 20s, terminates session & releases locks |
| poison | Transaction with row lock is returned to pool while still open | Bug where connections with open transactions are reused | Idle timeout never fires (connection is actively used). Transaction timeout fires after 40s, terminates session and releases locks |
Pool Mode: nopeers vs peers (2 PgBouncers)
| Mode | PgBouncer Config | Cancel Behavior |
|---|---|---|
| nopeers | Independent PgBouncers (no peer awareness) | Cancel requests may route to wrong PgBouncer via load balancer |
| peers | PgBouncer peers enabled (cancel key sharing) | Cancel requests are forwarded to correct peer |
Summary
| PgBouncers | Failure Mode | Pool Mode | Expected Outcome |
|---|---|---|---|
| 2 | poison | nopeers | Database-level Brownout or System Outage – TPS crashes to ~4, server connections max out at 95, TCP sockets accumulate in CLOSE_WAIT state, cl_waiting spikes |
| 1 | poison | nopeers | Row-level Brownout – TPS drops with no recovery (~11), server connections stay healthy at ~11, no server connection exhaustion |
| 2 | poison | peers | Row-level Brownout – TPS drops with no recovery (~15), cl_waiting stays at 0, peers forward cancels correctly |
| 2 | sleep | nopeers | Database-level Brownout or System Outage – Server connection spike to 96, full recovery after lock released and some extra time, system outage vs brownout depends on how quickly the idle timeout releases lock |
| 2 | sleep | peers | Row-level Brownout – No connection spike, full recovery after lock released, no risk of system outage |
Test Results
Transactions Per Second
TPS is the best indicator of actual application impact. It’s important to notice that PgBouncer peering does not prevent application impact from either poisoned connection pools or sleeping sessions. The section below titled “Detection and Prevention” has ideas which address the actual root cause and truly prevent application impact.
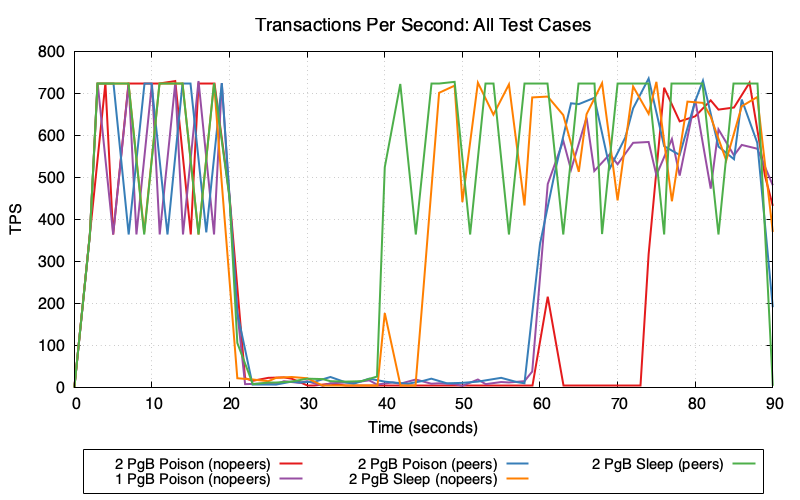
After the lock is acquired at t=20, TPS drops from ~700 to near zero in all cases as workers block on the locked row held by the open transaction.
Sleep mode (orange/green lines): Around t=40, Postgres’s idle_in_transaction_session_timeout (20s) fires and kills the blocking session. TPS recovers to ~600-700.
Poison mode (red/purple/blue lines): The lock-holding connection is never idle—it’s constantly being picked up by workers attempting queries—so the idle timeout never fires. TPS remains near zero until Postgres’s transaction_timeout (40s) fires at t=60, finally terminating the long-running transaction and releasing the lock.
TCP CLOSE-WAIT Accumulation
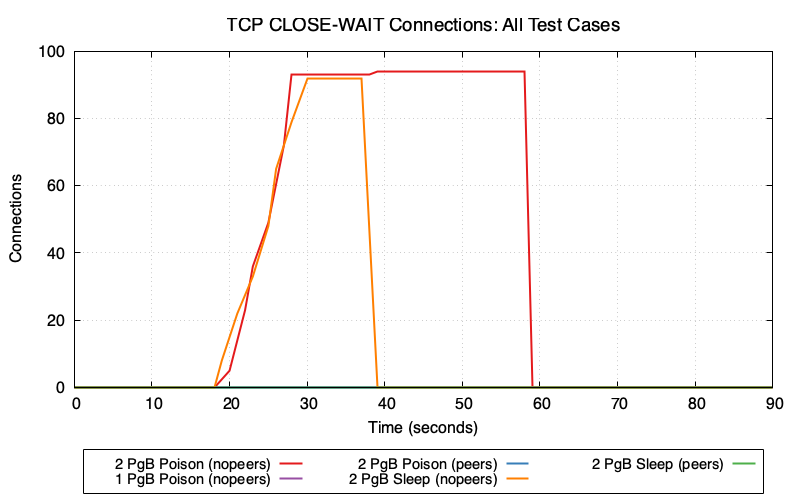
2 PgBouncers (nopeers) (red/orange lines): CLOSE_WAIT connections accumulate rapidly because:
- Cancel request goes to wrong PgBouncer → fails
- Client gives up and closes socket
- Server backend is still blocked on lock, hasn’t read the TCP close
- Connection enters CLOSE_WAIT state on Postgres
In poison mode (red), CLOSE_WAIT remains at ~95 until transaction_timeout fires at t=60. In sleep mode (orange), CLOSE_WAIT clears around t=40 when idle_in_transaction_session_timeout fires.
1 PgBouncer and peers modes (purple/blue/green lines): Minimal or zero CLOSE_WAIT because cancel requests succeed—either routing to the single PgBouncer or being forwarded to the correct peer.
Connection Pool Wait Time vs PgBouncer Client Wait
Go’s database/sql pool tracks how long goroutines wait to acquire a connection (db.Stats().WaitDuration). PgBouncer tracks cl_waiting—clients waiting for a server connection. These metrics measure wait time at different layers of the stack.

This graph shows 2 PgBouncers in poison mode (nopeers)—the worst-case scenario:
- Total Connections (brown) climb rapidly after poison injection at t=20 as failed cancels leave backends in CLOSE_WAIT
- TPS (green) crashes to near zero and stays there until
transaction_timeoutfires at t=60 - oldest_xact_age (purple) climbs steadily from 0 to 40 seconds
- Once Postgres hits
max_connections - superuser_reserved_connections(95), new connections are refused - PgBouncer #1 cl_waiting (red) then spikes as clients queue up waiting for available connections
- AvgWait (blue) increases as workers wait for the non-blocked connections to become available
Note the gap between when transaction_timeout fires (t=60, visible as oldest_xact_age dropping to 0) and when TPS fully recovers. TPS recovery correlates with cl_waiting dropping back to zero—PgBouncer needs time to clear the queue of waiting clients and re-establish healthy connection flow. This recovery gap only occurs in nopeers mode; the TPS comparison graph shows that peers mode recovers immediately when the lock is released because connections never exhaust and cl_waiting stays at zero.
Why is AvgWait (blue) so low despite the system being in distress? The poisoned connection (holding the lock) continues executing transactions without blocking—it already holds the lock, so its queries succeed immediately. This one connection cycling rapidly through the pool with sub-millisecond wait times heavily skews the average lower, masking the fact that other connections are blocked.
The cl_waiting metric is collected as cnpg_pgbouncer_pools_cl_waiting from CloudNativePG. See CNPG PgBouncer metrics.
Detection and Prevention
Monitoring and Alerting:
Alert on:
- Number of backends waiting on locks over some threshold
cnpg_backends_totalshowing established connections at a high percentage ofmax_connectionscnpg_backends_max_tx_duration_secondsshowing transactions open for longer than some threshold (nb. long-running queries are often legitimate)
-- Count backends waiting on locks
SELECT count(*) FROM pg_stat_activity WHERE wait_event_type = 'Lock';
Prevention Options:
Options to prevent the root cause (connection pool poisoning):
- Find and fix connection leaks in the application – ensure all transactions are properly committed or rolled back
- Use
OptionResetSessioncallback – automatically discard leaked connections (see below) - Fix at the driver level – PR #2481 adds automatic detection in pgx
Options to prevent the escalation from row-level brownout to system outage:
- Enable PgBouncer peering – if using multiple PgBouncers behind a load balancer, configure the
peer_idand[peers]section so cancel requests are forwarded to the correct instance (see PgBouncer documentation). This prevents connection exhaustion but does not prevent the TPS drop from lock contention. - Use session affinity (sticky sessions) in the load balancer based on client IP – ensures cancel requests route to the same PgBouncer as the original connection (see HAProxy Session Affinity example below)
Options to limit the duration/impact:
- Set appropriate timeout defaults – configure system-wide timeouts to automatically terminate problematic sessions:
idle_in_transaction_session_timeout– terminates sessions idle in a transaction (e.g.,5min)transaction_timeout(Postgres 17+) – use caution; limits total transaction duration regardless of activity (e.g.,30min)
Postgres:
Edit Feb 5: Postgres setting client_connection_check_interval enables dead connection cleanup.
Results Summary, Understanding the Layers Leading to the System Outage, Unique Problems, and more - available in the full writeup at https://github.com/ardentperf/pg-idle-test/tree/main/conn_exhaustion




Discussion
Trackbacks/Pingbacks
Pingback: Postgres client_connection_check_interval | Ardent Performance Computing - February 4, 2026