Wow – the last three weeks have been crazy! During the last week of May I was wrapping up the services paper and a few submissions for the UKOUG. And for the first two weeks of June I’ve been working on some performance problems for one of our clients in the Phoenix area. Nice weather but lots of work!
Turns out that the system I’m working on is running Oracle on NFS – one of Kevin Closson’s favorite causes. In fact he recently wrote a blog post on the topic of monitoring tools for this exact environment. He must have listed more than 50 tools and yet said “if you are using Oracle over NFS, there are a few network monitoring tools out there – I don’t like any of them.”
After last week I couldn’t agree more. Perhaps one of the most useful tools on linux for working with I/O is the iostat OS utility – but it’s entirely useless for NFS devices. However I really wanted to see exactly what the I/O patterns looked like – from the physical device perspective.
To make things more complicated, this server only has a single NIC which is being shared for everything. While I sympathize with Kevin’s argument that NFS keeps things simple, I’m not sure I could recommend this configuration… it can make things a little tricky to troubleshoot. Kevin has a script in his blog post that displays activity on an ethernet port similar to the way iostat monitors block devices – however in this case I need to only look at traffic to one particular IP address. So what’s a boy to do?
Traffic Graphs for NFS Devices
Well I did end up figuring something out – and with a few clicks in excel got some decent graphs too. There are actually two NetApp Filers being used (the redo logs were split onto a different head) and I was able to separate out read and write traffic to each head. Here’s what I was able to get for Tue, Wed, and Thu of last week:
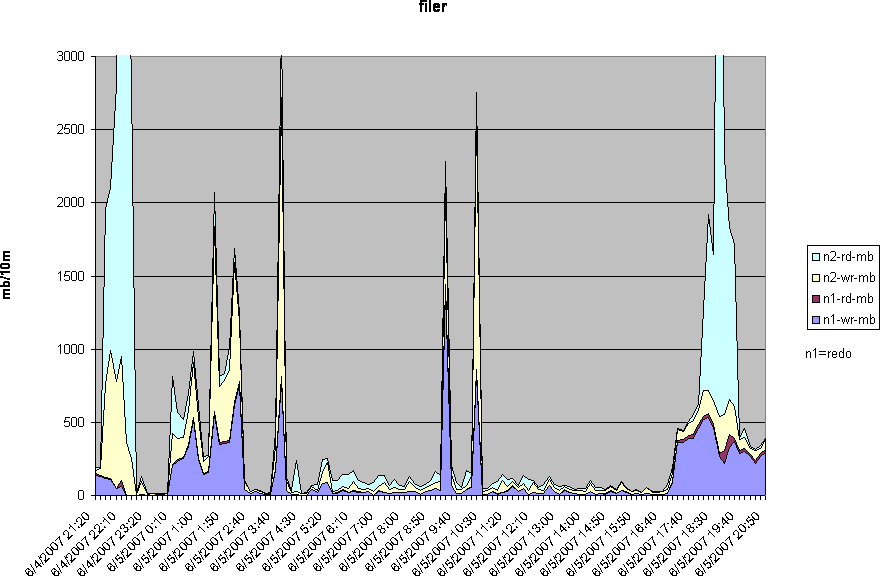


Moving the redo logs to a different head actually fits nicely with another post Kevin recently put together discussing how sequential writes can decimate the cache on a Filer… however I don’t think that this storage configuration was quite architected the way Kevin had in mind. When the system had been set up, the guys who configured it (who I don’t think are even around anymore) bought NetApp’s story – hook, line and sinker – that there’s no reason to have more than one huge double-parity aggregate. So the main production filer is one big aggregate of eleven 144G 10Krpm disks plus two parity disks, shared between the oracle database running the company’s core business and exchange… so that whenever anyone emails a big attachment the database potentially loses a few iops. And of course at some point they decided to move the redo logs off to the filer for less important apps – with one big aggregate of twenty-three 500G 7.2Krpm disks plus four parity disks. The online logs are sharing those huge, slow disks with dozens of other dev and prod applications.
The Approach
But anyway – the real story: how can you get cool graphs like that for an NFS device? What I really wanted was to see I/O stats for each mountpoint; however the solution I came up with was limited to each MAC address. (Note that this means that you have multiple filers and they’re not on the same subnet as your server then their statistics will be aggregated.) I ended up using the iptraf package to get the info I wanted – which is included on the RedHat media although it’s not installed by default. SystemTap (similar to DTrace, but on Linux) would be an even cooler (and lower-overhead) way to get this info however it requires a kernel patch which isn’t yet included in stock RHEL distributions.
Basically All I did was setup a cron job to launch iptraf every 10 minutes. It would then monitor and log all traffic on the interface (similar to tcpdump) for ten minutes then write out a log file. After this I wrote a quick script (with perl) to digest the log files and format them like sar. At that point it was easy to import the data into excel and make a few sexy graphs.
The biggest disadvantage to this approach is that iptraf uses a lot of CPU since it reads every single packet. On a 4-way box with 3GHz Xeon processors I’ve seen this process take about 5% of one CPU. Probably not something you want to leave running all the time – but very useful for collecting diagnostics info. This is why SystemTap uses a sampling methodology rather than inspecting every single packet.
The Source Code
The source code is pretty straightforward. We’ll start with the crontab. All it does is launch a small script.
[root@testbox1 iptraf]# crontab -l
# DO NOT EDIT THIS FILE - edit the master and reinstall.
# (cronjobs installed on Mon Jun 26 13:39:43 2006)
# (Cron version -- $Id: crontab.c,v 2.13 1994/01/17 03:20:37 vixie Exp $)
#
*/10 * * * * /root/ipt.sh
There are still a few snags with iptraf. I ran into two major ones while setting this up. First off, even if you’re launching iptraf in logging mode, for some dumb reason it still requires you to set the TERM variable to something where it could theoretically display pretty menus. I’ve chosen to take care of that here in the script.
The second problem is that iptraf actually gets the “in” and “out” backwards in the log. So when the log file says bytes came “in” to your server, they actually went out. That one drove me crazy… I seriously spent like two hours trying to figure out why we were reading so much data from the online logs. :)
Also, note that I’m putting all the log files into /var/log/iptraf and giving them names that start with “lan_statistics” and have the current time. It shouldn’t fill up your disk but it does generate a decent amount of data. It will generate more data if your box talks to more distinct MAC addresses.
[root@testbox1 iptraf]# cat /root/ipt.sh
#!/bin/sh
TERM=linux; export TERM
/usr/bin/iptraf -l eth0 -t 10 -B -L /var/log/iptraf/lan_statistics-$(date +%d-%H%M)
That’s all you need to generate the logs. Next step is to digest them. A short script should do the job here. A couple notes about this script:
-
I added a little code to read the arp table and try to resolve any MAC addresses into IP addresses that I can. If an entry has been aged out of the OS arp cache then it won’t be possible but for high-traffic addresses (like the filers) this is a big help.
-
The variable “min_bytes_rpt” is a threshold that can be used to eliminate clients with very little traffic. Useful if you’re just looking to see big hitters.
-
I’ve converted traffic to MB rather than bytes. This helped make my graphs more readable; easy enough to change back if you’d rather have it the other way.
-
I hardcoded the year and month in there. Should be trivial to fix; I was just focused on getting data for this week so it wasn’t a big deal. Maybe next time I use this script I’ll post an updated version.
[root@testbox1 iptraf]# cat rpt_iptraf.pl
#!/usr/bin/perl
my $dirname = "/var/log/iptraf/";
my $filemask = "lan_statistics-(..)-(..)(..)"; # $1 is day, $2 is hour, $3 is min
my $min_bytes_rpt = 0; #102400;
my $unknown_ip = "unknown";
print "date time ip hwaddr ipkt imbyt iip opkt ombyt oip ikbps okbps ikbps5s okbps5sn";
open(STDOUT,"|sort");
opendir(DIR, $dirname) or die "Directory '$dir' doesn't exist.";
open(ARP, "arp -n|sed s/://g|") or die "Can't run arp";
@arpcache = ;
close(ARP);
while (defined($file = readdir(DIR))) {
if($file =~ $filemask) {
my $day = $1;
my $hour = $2;
my $min = $3 + 10;
if($min==60) {$min=0;$hour++;};
if($hour==24) {$hour=0;$day++;};
open(DATA,$file);
while() {
if(/Ethernet address/) {
chomp;
my @words = split(/ +/);
my $hwaddr = $words[2];
my $ipaddr = $unknown_ip;
for(@arpcache) {
if($_ =~ /$hwaddr/i) {
@words = split(/ +/);
$ipaddr = $words[0];
last;
}
}
@words = split(/ +/,);
my $ipkt = $words[2];
my $ibyt = $words[4];
my $iip = $words[6];
@words = split(/ +/,);
my $opkt = $words[2];
my $obyt = $words[4];
my $oip = $words[6];
@words = split(/ +/,);
my $ikbps = $words[2];
my $okbps = $words[5];
@words = split(/ +/,);
my $ikbps5s = $words[3];
my $okbps5s = $words[6];
next if($ibyt + $obyt < $min_bytes_rpt);
printf "2007-06-%02s %02s:%02s", $day, $hour, $min;
printf " %s %s %s %s %s", $ipaddr, $hwaddr, $ipkt, $ibyt / 1024 / 1024, $iip;
printf " %s %s %s %s %s %s %sn", $opkt, $obyt / 1024 / 1024, $oip, $ikbps, $okbps, $ikbps5s, $okbps5s;
}
}
}
}
closedir(DIR);
close(STDOUT);
Putting It Together
When you put it all together you get something like this:
[root@testbox1 iptraf]# ./rpt_iptraf.pl
date time ip hwaddr ipkt imbyt iip opkt ombyt oip ikbps okbps ikbps5s okbps5s
2007-06-04 21:10 10.1.1.41 02a098040a6e 112339 132.477376937866 112339 55520 7.18408012390137 55519 1852.17 100.44 2160.60 118.60
2007-06-04 21:20 10.1.1.41 02a098040a6e 118304 139.65291595459 118304 58508 7.59678649902344 58508 1952.49 106.21 2733.60 142.20
2007-06-04 21:30 10.1.1.41 02a098040a6e 111168 128.729362487793 111168 56262 9.77060699462891 56262 1799.77 136.60 2354.60 131.00
2007-06-04 21:40 10.1.1.41 02a098040a6e 101004 116.906017303467 101004 49337 6.51760482788086 49336 1634.46 91.12 2893.80 156.60
2007-06-04 21:50 10.1.1.41 02a098040a6e 101269 109.48544883728 101269 47815 6.82938194274902 47815 1530.72 95.48 2606.00 144.40
2007-06-04 22:00 10.1.1.41 02a098040a6e 42982 45.4206047058105 42982 19575 2.74732398986816 19575 635.02 38.41 19.60 2.40
2007-06-04 22:10 10.1.1.41 02a098040a6e 62191 63.6640911102295 62191 50385 39.0000438690186 50385 890.09 545.26 552.80 26.40
2007-06-04 22:30 10.1.1.41 02a098040a6e 1064 1.41771697998047 1064 599 0.0759639739990234 599 19.82 1.06 0.80 0.60
2007-06-04 22:40 10.1.1.41 02a098040a6e 62 0.0524177551269531 62 36 0.0047454833984375 36 0.73 0.07 0.00 0.00
2007-06-04 22:50 10.1.1.41 02a098040a6e 72 0.061431884765625 72 43 0.00582122802734375 42 0.86 0.08 1.80 1.40
2007-06-04 23:10 10.1.1.41 02a098040a6e 2172 3.63872528076172 2172 1550 0.179790496826172 1550 50.87 2.51 0.00 0.00
2007-06-04 23:20 10.1.1.41 02a098040a6e 101 0.104799270629883 101 57 0.00864028930664062 56 1.47 0.12 0.00 0.00
2007-06-04 23:30 10.1.1.41 02a098040a6e 89 0.0909519195556641 89 48 0.007354736328125 48 1.27 0.10 0.00 0.00
2007-06-04 23:40 10.1.1.41 02a098040a6e 78 0.0770759582519531 78 44 0.00710296630859375 44 1.08 0.10 0.00 0.00
2007-06-04 23:50 10.1.1.41 02a098040a6e 54 0.0451011657714844 54 32 0.00499916076660156 31 0.63 0.07 10.00 1.40
2007-06-05 00:00 10.1.1.41 02a098040a6e 485 0.620027542114258 485 267 0.0409374237060547 267 8.67 0.57 0.00 0.00
2007-06-05 00:10 10.1.1.41 02a098040a6e 96539 201.982706069946 96539 91238 10.4953727722168 91238 2823.92 146.74 1830.00 61.40
2007-06-05 00:20 10.1.1.41 02a098040a6e 141277 235.408586502075 141277 90526 7.35157012939453 90526 3291.25 102.78 3147.00 88.80
2007-06-05 00:30 10.1.1.41 02a098040a6e 151695 251.017206192017 151695 95481 7.9734058380127 95481 3509.47 111.47 2869.20 84.60
2007-06-05 00:40 10.1.1.41 02a098040a6e 242440 335.305465698242 242440 120891 9.87641716003418 120891 4687.91 138.08 5594.00 169.80
2007-06-05 00:50 10.1.1.41 02a098040a6e 373762 518.220848083496 373762 181776 15.6355056762695 181776 7245.25 218.60 3574.00 106.80
2007-06-05 01:00 10.1.1.41 02a098040a6e 179130 248.385322570801 179130 88858 7.41687393188477 88858 3472.68 103.69 2284.80 65.80
2007-06-05 01:10 10.1.1.41 02a098040a6e 106062 146.54764175415 106062 53160 4.30619430541992 53160 2048.88 60.20 1394.40 44.80
2007-06-05 01:20 10.1.1.41 02a098040a6e 113538 157.074638366699 113538 57125 4.69901466369629 57125 2196.06 65.70 2351.60 75.00
2007-06-05 01:30 10.1.1.41 02a098040a6e 397334 554.866077423096 397334 200090 16.6406326293945 200090 7757.59 232.65 2605.60 75.20
2007-06-05 01:40 10.1.1.41 02a098040a6e 250720 350.910491943359 250720 122871 10.1241588592529 122871 4906.08 141.54 5602.00 168.40
2007-06-05 01:50 10.1.1.41 02a098040a6e 256261 358.590078353882 256261 123853 11.0274143218994 123853 5013.45 154.17 1405.20 42.80
2007-06-05 02:00 10.1.1.41 02a098040a6e 260270 365.149021148682 260270 138676 11.4949340820312 138676 5105.15 160.71 1107.80 35.40
2007-06-05 02:10 10.1.1.41 02a098040a6e 438086 615.684860229492 438086 232442 19.603931427002 232442 8607.90 274.08 1731.40 54.20
So that’s about it. And I’ve just blown about an hour writing this post that I probably shouldn’t have… time to get to work. :) Hope someone finds this useful!




Excellent post. Thanks Jeremy.
LikeLike
Posted by Alex Gorbachev | June 14, 2007, 6:58 pm