Well it’s been awhile since I’ve written anything for the blog – during the past four months I went on a trip to Asia, celebrated Thanksgiving and Christmas with both my family and my girlfriend’s family and then in January I got engaged! I’ve also been working on some continuing educational goals – so needless to say I’ve been keeping busy. And I will continue to be very busy over the next few months of wedding planning so I probably won’t be writing too much.
This post is just another interesting case study from a customer I’m working with right now. We were looking at various queues in the I/O stream and wondering how we might be able to tweak them. I was mainly investigating the host HBA’s – but in the process of digging into this I also learned about few other queues and Linux internals in general as it relates to Oracle.
Direct Async I/O
 It’s pretty well documented that the most efficient configuration for Oracle is direct asynchronous I/O.
It’s pretty well documented that the most efficient configuration for Oracle is direct asynchronous I/O.
Direct I/O means to avoid unnecessarily copying bits from one memory location to another between the hardware and the SGA. Every flavor of Unix implements some form of caching for block devices and filesystems; in Linux the buffer cache (for block devices) or page cache (for filesystem data) can cache database blocks. Most applications benefit from this caching – however Oracle does not. There are two primary reasons this caching is bad for Oracle:
-
Oracle caches this data itself in the SGA and it does a far better job of predicting what blocks will be best retained in memory. When the OS caches data you essentially end up with two copies of every data block – one that’s really unused. You waste half the memory in your server with almost no performance benefit.
-
The data has to be copied extra times before arriving in the SGA – and these extra “copy” operations slow down your read operations.
Asynchronous I/O means to multitask your read and write operations. Remember how in MSDOS you could only run one program at a time? Believe it or not, this is how most Unix filesystems do I/O by default – one thing at a time. Using Asynchronous is equivalent to upgrading to an Operating System that allows you to run more than one program at a time. It allows Oracle to issue multiple read and write operations concurrently – this is obviously more efficient.
There are different ways of implementing Direct I/O and Asynchronous I/O in different environments (CIO, QIO, ODM, etc) – but it’s always best to enable them and then shift memory from the OS caches to the SGA.
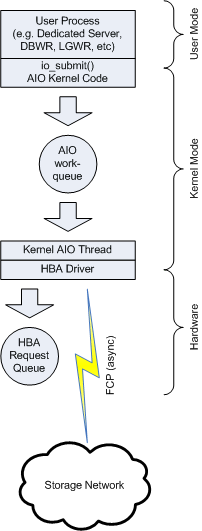
The Linux I/O Path
I should start out by saying that I’m not a kernel expert. After some digging through source code and mailing lists I think that I’ve got a handle on the main concepts here – but I’m open to correction since this is complicated stuff and I easily could miss some details of how it’s all implemented! Let me know if you have anything to add!
On Linux, asynchronous I/O requests are submitted through the io_submit() call. (Kevin Closson once wrote about tracing this call.) This function essentially puts the I/O request into a queue which is managed by the Linux kernel. I think that this workqueue is a generic kernel object which you can’t and shouldn’t need to tweak. The I/O request is subsequently picked up by one of several kernel AIO background processes and serviced.
What the kernel thread does depends on the underlying device. FC cards support asynchronous requests to the target (it’s part of the SCSI spec) – so in this case the kernel thread will issue a number of SCSI read or write requests in parallel. This is where a second queue comes in! And this queue, unlike the kernel workqueues, can be tweaked.
The target device (Symetrix, DSxxxx, 3Par, etc) also has an FC port which has its own queue for I/O requests that are being serviced. On a 3par device these ports only have between 500 and 2000 slots for concurrent I/O requests depending on the model. This means that all the servers accessing any LUNs over that port cannot issue more than 500-2000 concurrent I/O requests – or you will start to see “QUEUE FULL SCSI” errors.
My best guess: this means that the default limit set by the Linux qla2xxx driver for concurrent I/O requests on QLogic cards (32 per LUN) is conservative. The driver sets this limit by limiting the size of the queue. So naturally… my next question was if I could increase performance by increasing this limit…
Tweaking the HBA Queue Depth
I did run a few tests – but I think I’ll save the results for a second post since this one has already gotten pretty long. Any guesses about what the results were?




> in January I got engaged
Congratulations Jeremy :)
LikeLike
Posted by TongucY | February 1, 2008, 3:48 amI was worried that you were stuck in some Thai prison.
Welcome back and congrats.
LikeLike
Posted by Don Seiler | February 1, 2008, 11:50 amThaks to your more details for I/O request.
And right now I am learning oracle, sometimes I get it really difficult to me.
But I will never give up.
congrautlations!
LikeLike
Posted by Ken | April 15, 2008, 7:50 amThanks for a clear description of the IO system.
would you know how oracle is changing its requests from the IO_SUBMIT() when it executing Db files sequential read or Db file scattered read ?
LikeLike
Posted by Nir | September 24, 2008, 2:46 amFor me, the best operating system is Linux because it rarely hangs.’`’
LikeLike
Posted by Leah Perez | May 20, 2010, 11:09 am