This month’s PGSQL Phriday #015 topic is about UUIDs, hosted by Lætitia Avrot. Lætitia has called for a debate. No, no, no. I say let’s have an all-out war. A benchmark war.
I have decided to orchestrate a benchmark war between four different methods of storing a primary key:
- use a text field to store UUIDs
- use PostgreSQL’s native
uuiddata type - use the new uuidv7 code currently in CommitFest which we’re hoping will be in PostgreSQL 17 (i think we might still be waiting on something related to the approval process for the official standard)
- use the classic, efficient, fast, sql-standard
bigint generated as identitydata type.
The challenge is simple: insert one million rows into a large table, while concurrently querying it, AS FAST AS YOU CAN!!!
Sadly I ran out of time. There’s one issue with my script, and I know how to fix it, but I need to get this blog published today or I won’t make the PGSQL Phriday cutoff!!
My problem is a bit amusing… the results successfully demonstrate how each option is better than the previous… until you get to bigint. I’ve demonstrated the size benefits of bigint but my uuidv7 performance is so good it basically matched bigint 😂 – but I’m guessing this is because my concurrent queries aren’t increasing cache pressure by using a uuid column yet… I suspect fixing this will demonstrate the performance gap between uuidv7 and bigint.
Regardless: there’s some good and useful stuff here – so let’s go ahead and dive in.
Edit 6-Feb-2024: This blog article had some great discussion and commentary over the past few days. In particular: lots of interesting discussion on HackerNews both here and here, and Rafael Ponte posted a fantastic summary/analysis in Portuguese on Twitter/X and LinkedIn. It’s all worth reading alongside this blog; lots of good feedback and follow-up ideas!
Edit 8-Feb-2024: Since I was trying to quickly write something to make the #PGSQLPhriday deadline, I didn’t do a thorough search for prior work last weekend. This topic is – of course – as old as dirt. Over on LinkedIn, Rafael Ponte pointed out that Tomas Vondra published https://2ndquadrant.com/en/blog/sequential-uuid-generators/ in 2018 and Bandur published https://brandur.org/nanoglyphs/026-ids in 2021. At a glance I can tell they are both very good articles (probably the most thorough I’ve seen so far). Adding links here now, and I’m going to set aside some time later to read closely.
Additionally… here are the follow-up ideas that I remember being suggested so far: both cached and uncached (Vladimir Michel Bacurau Magalhães), adding ULID (Carlos Alito), uuidv7/text (Mike Klaas), NewID (Rodion Mostovoi), querying on the uuid field instead of always bigint, trying BRIN for the query (solinvictvs on twitter), and evaluating impact on joins or comparisons (David Wheeler).
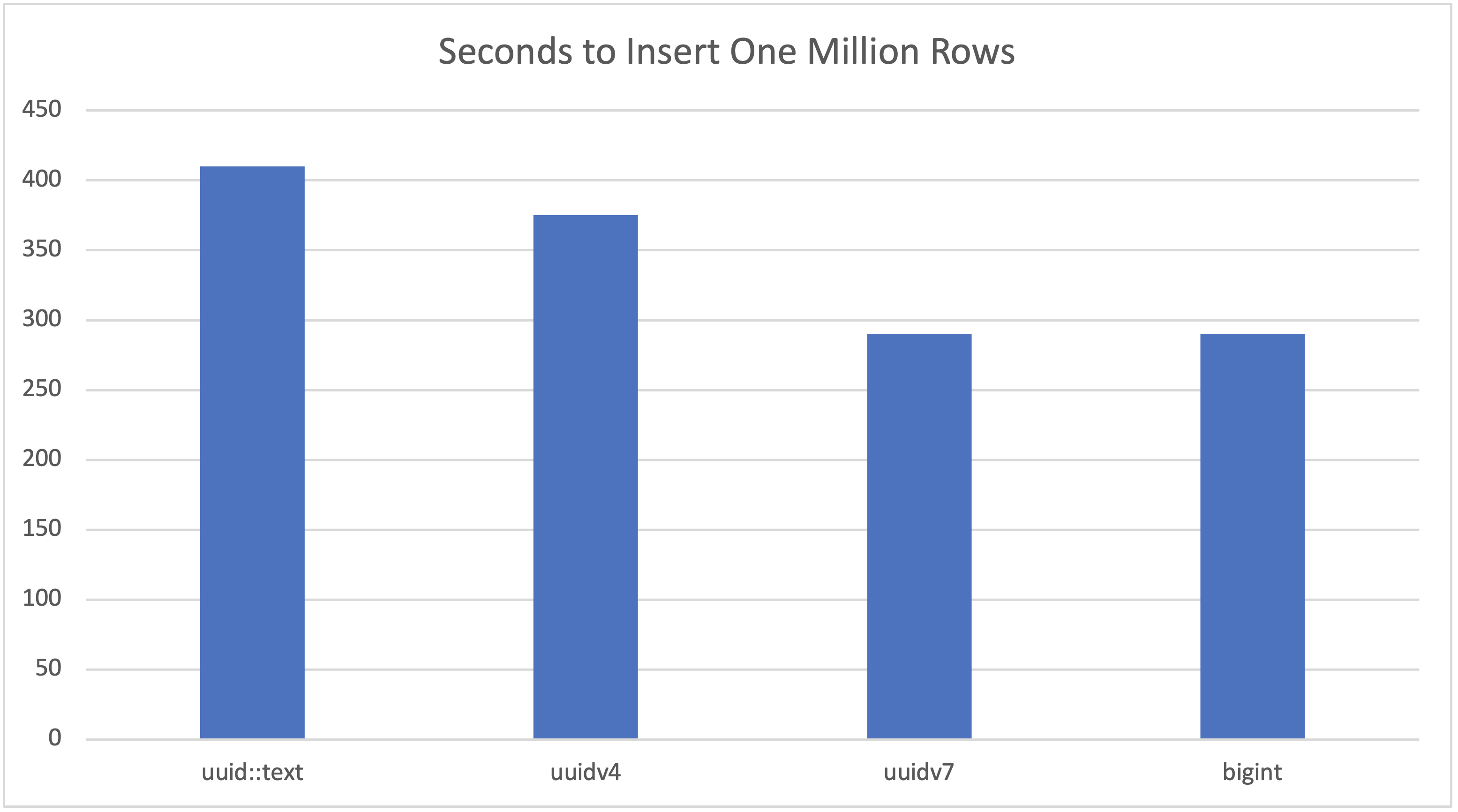
Results Summary
| Test | Time to Insert One Million Rows | Average Rate | Size at Finish | Performance and Size Improvement |
| uuid::text | 410 sec | 2421 tps | 4.31 gb | – |
| uuidv4 | 375 sec | 2670 tps | 2.65 gb | 10% faster and 63% smaller than text |
| uuidv7 | 290 sec | 3420 tps | 2.47 gb | 30% faster and 7% smaller than uuidv4 |
| bigint | 290 sec | 3480 tps | 1.97 gb | same speed (in this test) and 25% smaller than uuidv7 |

Setup Overview
This benchmark is fully scripted and reproducible, based on my Copy-and-Paste Postgres Dev Env. Anyone can reproduce with a few simple copy-and-paste steps; the full details are at the bottom of this blog post.
Processor: 1 full core AMD EPYC Genoa, 3.7 GHz, 1 thread per core, 2GB memory (ec2 c7a.medium)
Storage: 16k IOPS, 1000 MB/s Throughput, 100 GB (ebs gp3)
Operating System: Ubuntu 22.04 LTS, Kernel 6.2.0-1017-aws #17~22.04.1-Ubuntu
PostgreSQL: main development branch as of Jan 29 2024 with v17 of the UUIDv7 patch
Settings: shared_buffers=1G / max_wal_size=204800
Schema: single table with 3 columns (id, foreign_table_id and data::bigint), data type for id and foreign_table_id follows the test
Initial Table Size: 20 million rows
Aside: The new c7a/m7a/r7a EC2 instance family is interesting because of the switch to core-per-vCPU, similar to graviton. While the top-end r7i.48xlarge (intel) has 96 physical cores with hyperthreading, the top-end r7a.48xlarge (amd) is a beast with 192 physical cores and 1.5TB of memory. I look forward to playing with PostgreSQL on one of these machines someday. 🏇
Cost
While my copy-and-paste-dev-env defaults to the free tier, I switched to a non-bursting instance family and added some beefy gp3 storage for this performance test.
The storage is significantly over-provisioned and could definitely be scaled down on all three dimensions to save quite a bit of money. I was in a hurry to make the publishing deadline and didn’t take the time to optimize this part.
It took a total of 4 hours and 13 minutes to run the benchmark 3 times in a row. The setup steps are copy-and-paste and take less than 10 minutes so lets round up to 4.5 hours. I also repeated the full test (three loops) on a second server to verify performance consistency. According to the official AWS pricing calculator at calculator.aws this is the cost breakdown:
- ec2 r7a.medium on-demand pricing: $0.07608/hr
- ebs gp3 100GB 16k iops 100 MBps throughput: $0.14795/hr
- two servers complete benchmark in 4.5 hours = total 9 hours
GRAND TOTAL for both servers = US$ 2.02
Less than a cup of coffee.
Holy smokes batman – do we live in a different world than 20 years ago when it comes to the price of benchmarking or what?!! Also why is coffee so expensive?
Of course I had it running a bit longer while I was iterating and getting things ironed out, but I think the point stands. 🙂
Run Overview
Tests:
bigint generated by default as identity (cache 20)text default gen_random_uuid()uuid default gen_random_uuid()uuid default uuidv7()(current proposed syntax; may change before future release)
Workload:
INIT_TABLE_ROWS=20000000
PGBENCH_TRANSACTIONS_PER_CLIENT=100000
PGBENCH_CLIENTS=10
echo "
\set search_data random(1,$INIT_TABLE_ROWS)
insert into records(data) values(random()*$INIT_TABLE_ROWS);
select * from records where data=:search_data;
" >txn.sql
pgbench --no-vacuum --transactions=$PGBENCH_TRANSACTIONS_PER_CLIENT
--client=$PGBENCH_CLIENTS --file=txn.sql --progress=5 --report-per-command
>test_log.txt 2>&1Run Details
I ran the test on two servers, and on each server the whole test was repeated three times. Performance was consistent across both servers and all loops.
grep "tps," test_log.txt
One quick note – there is a dip in the TPS around 300 seconds. I haven’t verified in the logs but I suspect this is just the system checkpoint kicking in; I force a checkpoint right before starting each test and PostgreSQL defaults to 5 minute intervals. (And we increased the max_wal_size so that we wouldn’t get an early checkpoint.)
The data load of 20 million records took significantly longer for uuid::text than the other tests, which is reflected in the table sizes tracked over time.
while true; do
psql --csv -Xtc "select extract(epoch from now()), relname,
pg_relation_size(oid)
from pg_class where relname like 'records%'
"
sleep 15
done >relation_sizes.csv
The best way to get a fast, high-level look at what’s happening internally with PosgreSQL is to use wait events. We will zoom in on the higlighted section above, with uuid runs from the first loop and bigint from the second loop.
It’s immediately obvious that the biggest difference between the runs is the amount of time spent in IO:DataFileRead by database connections executing SQL.
while true; do
psql --csv -Xtc "select extract(epoch from now()),query,wait_event_type,wait_event
from pg_stat_activity
where (application_name='pgbench' or query like 'insert%')
and state='active';
"
sleep 15
done >wait_events.csv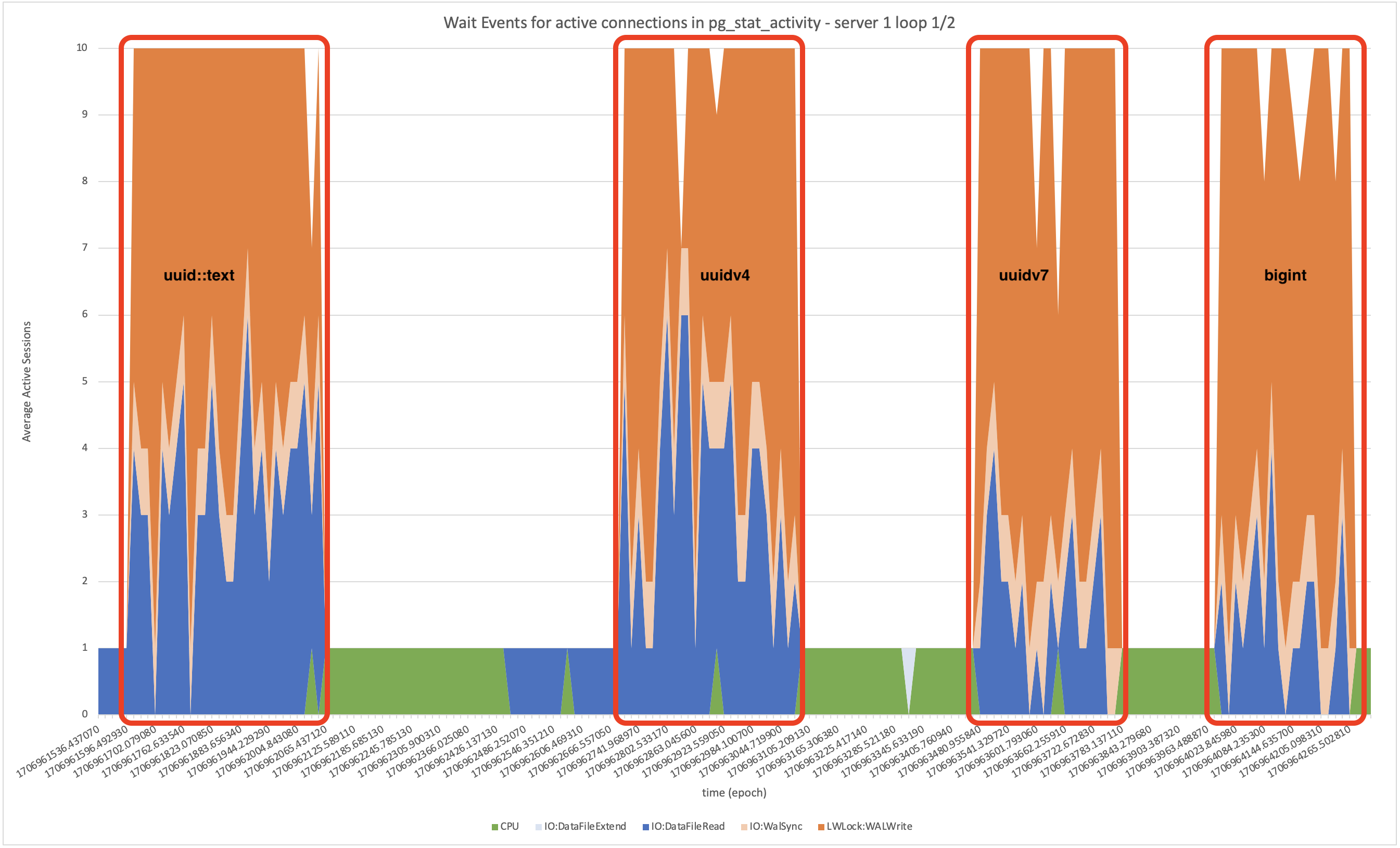
We need to read blocks from the disk when they are not in the PostgreSQL buffer cache. Conveniently, PostgreSQL makes it very easy to inspect the contents of the buffer cache. This is where the big difference between uuidv4 and uuidv7 becomes clear. Because of the lack of data locality in uuidv4 data, the primary key index is consuming a huge amount of the buffer cache in order to support new data being inserted – and this cache space is no longer available for other indexes and tables, and this significantly slows down the entire workload. Putting it another way: for some workloads uuidv4 significantly increases the total working set size.
while true; do
psql --csv -Xtc "create extension if not exists pg_buffercache" -c "
SELECT extract(epoch from now()), n.nspname, c.relname, count(*) AS buffers
FROM pg_buffercache b JOIN pg_class c
ON b.relfilenode = pg_relation_filenode(c.oid) AND
b.reldatabase IN (0, (SELECT oid FROM pg_database
WHERE datname = current_database()))
JOIN pg_namespace n ON n.oid = c.relnamespace
GROUP BY n.nspname, c.relname
ORDER BY count(*) DESC
LIMIT 10;
"
sleep 15
done >buffer_cache.csv
PostgreSQL uses a clock sweep algorithm to manage its cache. This is different from the linux page cache active/inactive system; PostgreSQL tracks a “usage count” on each buffer that can range from 0 to 5. The usage count is incremented any time a block already in the cache is used, and decremented any time a connection needs to use a block that isn’t currently in the cache – it sweeps through the cache and looks for a block that’s eligible for eviction, decrementing usage counts as it goes. Hot blocks like index root nodes naturally maintain a high usage count and stay in the cache. Cache management algorithms are always an interesting topic (for example, see Marc Brooker’s recent blog article about SIEVE). I am a fan of PostgreSQL’s current algorithm – I think it works well and it’s easy to understand and reason about.
Not too long ago, Nathan Bossart added a very light-weight function to PostgreSQL to allow more detailed inspection of usage count data. Lets see what it looked like for this zoomed in time window.
while true; do
psql --csv -Xtc "SELECT extract(epoch from now()),* FROM pg_buffercache_usage_counts();"
sleep 15
done >usage_counts.csv
I’ve looked at a number of charts like this from different workloads over the past year or two. My experience has been that when the data set fits in the cache we see everything at usage count 5 (as expected), and when the working set is larger than the cache there’s always a spectrum between hot and cold similar to this picture. And the balance across the spectrum reflects the balance of pressure between hits and misses on the cache. I’ve seen where a single large query can cause a spike in lower-usage-count buffers, and then the lines slope back downward as the workload pushes usage counts back up. In this particular workload, we see the large blocks of usage count 5 during initial data load before the data set reaches 1GB and we see the spectrum of usage counts once it exceeds 1GB. During the benchmark itself, the lines slope very slightly upward because our benchmark is adding a million rows, so we’re slowly increasing the total working set size, which causes more cache miss pressure relative to cache hits.
Interesting stuff! Hope this makes it clear why you should never store your UUIDs in a text field, and why some of us are excited for uuidv7 when it’s eventually ready. It should also be clear how even with uuidv7 there is still a total size penalty for choosing UUID (128-bit) over bigint (64-bit). And hopefully we can demonstrate at some point in the future how that can translate into performance impact for some workloads.
Full Benchmark Scripts
To run this benchmark, follow the instructions at Copy-and-Paste Postgres Dev Env with the following modifications:
| Open the web page Copy-and-Paste Postgres Dev Env and begin following those steps. Make the adjustments listed below. | |
| step1 | Copy the following command to switch to c7a.medium and a gp3 volume with the specs above:aws ec2 run-instances --region us-east-1 --key-name $KEY --instance-type c7a.medium --tag-specifications "ResourceType=instance,Tags=[{Key=Name,Value=pgdev}]" --image-id ami-0c7217cdde317cfec --block-device-mappings "DeviceName=/dev/sda1,Ebs={VolumeSize=100,VolumeType=gp3,Iops=16000,Throughput=1000}" |
| step4 | After checking out the PostgreSQL source code, copy the following commands to switch to a commit from January 29 2024 and apply v17 of the UUIDv7 patch from the PostgreSQL mailing lists.cd git/postgres—– The current commitfest entry for UUIDv7 is at https://commitfest.postgresql.org/47/4388/ v17 of the patch is available from this email https://www.postgresql.org/message-id/0906F8BA-CA52-4956-AA68-E9193E50DFDF%40yandex-team.ru You can see recent commits to the PostgreSQL main development branch at https://git.postgresql.org/gitweb/?p=postgresql.git;a=shortlog |
| step5 | After compiling PostgreSQL, copy the following commands to apply two custom parameters before we start running our benchmark.echo "max_wal_size=204800" >>$HOME/etc/postgres.d/postgresql.dev.conf |
| benchmark | The benchmark is very simple and straightforward. I’ve copied the code into a GIST that you can copy or download. https://gist.github.com/ardentperf/da1e10641983a94c51f3261f4890ffb1 The key bits for quick reference: create table records ( |




Nice. I’m curious about joins tho. If I have say 100m rows in a couple tables and am joining, say, 20m between them, what’s the difference in performance between int4, int8, and UUID?
This was a real issue at my last job, where we had queries selecting massive numbers of users, a significant subset of of our 150m, based on criteria stored in multiple tables. Was so ridiculous that performance fared better
WITH EXISTS IN (SELECT …)rather than joins.And with the index and table scans mostly just looking at IDs, there was real concern over potential performance differences due to identifier size.
LikeLiked by 1 person
Posted by David Wheeler | February 3, 2024, 4:37 pmI get why bigint is included, but it’s probably worth calling out that bigint is unsuitable for distributed systems where ids are generated by multiple hosts and uuid’s eliminate the risk of collision.
LikeLiked by 1 person
Posted by Ross Bagley | February 5, 2024, 9:30 amHi! Thanks a lot for these benchmarks. But what about NewID that is seqeuntial? It would be great to add into comparasion.
LikeLiked by 1 person
Posted by Rodion Mostovoi | February 7, 2024, 4:15 amI am not sure if I should only use UUIDs PKs instead of internal INT or BIGINT PKs and external UUIDs, because nobody does comparisons with queries specially joins.
LikeLike
Posted by Zistrious | January 24, 2026, 4:26 pm