This is the fifth article in a series called Operationally Scalable Practices. The first article gives an introduction and the second article contains a general overview. In short, this series suggests a comprehensive and cogent blueprint to best position organizations and DBAs for growth.
We’ve looked in some depth at the process of defining a standard platform with an eye toward Oracle database use cases. Before moving on, it would be worthwhile to briefly touch on clustering.
Most organizations should hold off as long as possible before bringing clusters into their infrastructure. Clusters introduce a very significant new level of complexity. They will immediately drive some very expensive training and/or hiring demands – in addition to the already-expensive software licenses and maintenance fees. There will also be new development and engineering needed – perhaps even within application code itself – to support running your apps on clusters. In some industries, clusters have been very well marketed and many small-to-medium companies have made premature deployments. (Admittedly, my advice to hold off is partly a reaction to this.)
When Clustering is Right
Nonetheless there definitely comes a point where clustering is the right move. There are four basic goals that drive cluster adoption:
- Parallel or distributed processing
- Fault tolerance
- Incremental growth
- Pooled resources for better utilization
I want to point out immediately that RAC is just one way of many ways to do clustering. Clustering can be done at many tiers (platform, database, application) and if you define it loosely then even an oracle database can be clustered in a number of ways.
Distributed Processing
Stop for a moment and re-read the list of goals above. If you wanted to design a system to meet these goals, what technology would you use? I already suggested clusters – but that might not have been what came to your mind first. How about grid computing? I once worked with some researchers in Illinois who wrote programs to simulate protein folding and DNS sequencing. They used the Illinois BioGrid – composed of servers and clusters managed independently by three different universities across the state. How about cloud computing? The Obama Campaign in 2008 used EC2 to build their volunteer logistics and coordination platforms to dramatically scale up and down very rapidly on demand. According to the book In Search of Clusters by Gregory Pfister, these four reasons are the main drivers for clustering – but if they also apply to grids and clouds then then what’s the difference? Doesn’t it all accomplish the same thing?
In fact the exact definition of “clustering” can be a little vague and there is a lot of overlap between clouds, grids, clusters – and simple groups of servers with strong & mature standards. In some cases these terms might be more interchangeable than you would expect. Nonetheless there are some general conventions. Here is what I have observed:
| CLUSTER | Old term, most strongly implies shared hardware resources of some kind, tight coupling and physical proximity of servers, and treatment of the group as a single unit for execution of tasks. While some level of single system image is presented to clients, each server may be individually administered and strong standards are desirable but not always implied. |
|---|---|
| GRID | Medium-aged term, implies looser coupling of servers, geographic dispersion, and perhaps cross-organizational ownership and administration. There will not be grid-wide standards for node configuration; individual nodes may be independently administered. The grid may be composed of multiple clusters. Strong standards do exist at a high level for management of jobs and inter-node communication.
Or, alternatively, the term “grid” may more loosely imply a group of servers where nodes/resources and jobs/services can easily be relocated as workload varies. |
| CLOUD | New term, implies service-based abstraction, virtualization and automation. It is extremely standardized with a bias toward enforcement through automation rather than policy. Servers are generally single-organization however service consumers are often external. Related to the term “utility computing” or the “as a service” terms (Software/SaaS, Platform/PaaS, Database/DaaS, Infrastructure/IaaS).
Or, alternatively, may (like “grid”) more loosely imply a group of servers where nodes/resources and jobs/services can easily be relocated as workload varies. |
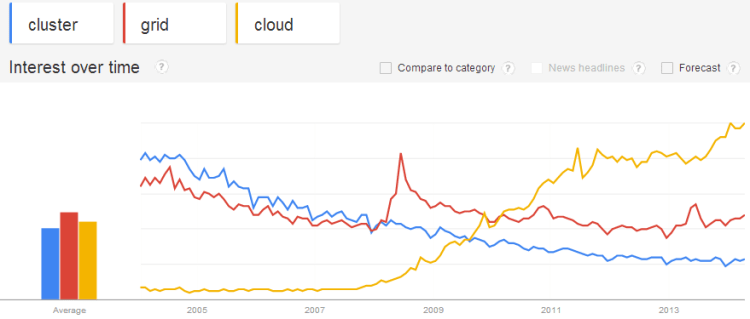
Google Trends for Computers and Electronics Category
These days, the distributed processing field is a very exciting place because the technology is advancing rapidly on all fronts. Traditional relational databases are dealing with increasingly massive data volumes, and big data technology combined with pay-as-you-go cloud platforms and mature automation toolkits have given bootstrapped startups unforeseen access to extremely large-scale data processing.
Building for Distributed Processing
Your business probably does not have big data. But the business case for some level of distributed processing will probably find you eventually. As I pointed out before, the standards and driving principles at very large organizations can benefit your commodity servers right now and eliminate many growing pains down the road.
In the second half of this article I will take a look at how this specifically applies to clustered Oracle databases. But I’m curious, are your server build standards ready for distributed processing? Could they accommodate clustering, grids or clouds? What kinds of standards do you think are most important to be ready for distributed processing?




Discussion
Comments are closed.