Hello, let me introduce myself. Today, we’ll pretend that I’m a linguistics researcher. I don’t know much about databases, but I do know a lot about the Balti language of northern Pakistan. That’s why I’m excited about my current translation project.
The most interesting part of this translation project is that I’m doing some computer-driven analysis of a large body of text in the Balti language. For that, I’m going to need a database. You – dear friend – will help me with this! (Because you are an expert with databases!)
Our favorite database is PostgreSQL, so we should use it for my analysis work. You create an EC2 instance running an LTS release of Ubuntu and you create a database for me on the instance:
aws ec2 run-instances --key-name mac --instance-type t2.micro --tag-specifications 'ResourceType=instance,Tags=[{Key=Name,Value=research-db}]' --image-id ami-0172070f66a8ebe63 --region us-east-1
sudo apt install postgresql-common
sudo sh /usr/share/postgresql-common/pgdg/apt.postgresql.org.sh
sudo apt install postgresql-15
create database research_texts template=template0 locale_provider=icu icu_locale="en-US"Pretty easy!
Now I expect to be loading a very large amount of data for analysis. With a little help, I got DBeaver running on my computer and a connection to our “research_texts” database. After some discussion we decide that I should partition the main table, which has a huge list of Balti words along with cross-references and notes for each one.
As the wikipedia page for Balti explains, most people in this region of Pakistan use a Perso-Arabic alphabet which has between 40 and 50 characters. We’ll divide my table into four partitions, with about a quarter of the alphabet each. (And just to be safe we’ll add a default partition as well.)
create table arabic_dictionary_research (
word text,
crossreferences text,
notes text
) partition by range (word);
create table arabic_dictionary_research_p1 partition of arabic_dictionary_research
for values from ('ا') to ('ح');
create table arabic_dictionary_research_p2 partition of arabic_dictionary_research
for values from ('ح') to ('س');
create table arabic_dictionary_research_p3 partition of arabic_dictionary_research
for values from ('س') to ('ل');
create table arabic_dictionary_research_p4 partition of arabic_dictionary_research
for values from ('ل') to ('ے');
create table arabic_dictionary_research_p5 partition of arabic_dictionary_research
default;And finally my work begins! This isn’t my real research, but lets put some example data into the table to get an idea what it might look like.
insert into arabic_dictionary_research
select 'ب'||generate_series(1,1000), repeat('important cross-references!',100), 'notes'
union all
select 'د'||generate_series(1,1000), repeat('important cross-references!',100), 'notes'
union all
select 'م'||generate_series(1,1000), repeat('important cross-references!',100), 'notes'
union all
select 'ࣈ'||generate_series(1,1000), repeat('important cross-references!',100), 'notes'
union all
select 'ق'||generate_series(1,1000), repeat('important cross-references!',100), 'notes'
union all
select 'ٶ'||generate_series(1,1000), repeat('important cross-references!',100), 'notes'
;
select word,length(crossreferences),notes from arabic_dictionary_research where word='د100';
select word,length(crossreferences),notes from arabic_dictionary_research where word='ࣈ100';
Update 27-Mar-2023: I published this article over the weekend using my personal computer at home. When I got to work this morning I glanced at the article and saw a square box appearing in many SQL queries where I expected to see the Perso-Arabic letter Graf. That character displays correctly from my home computer (macOS 13 Ventura) and my iPhone (iOS 16) but not on my work laptop (macOS 12 Monterey). I now realize that many readers of this article will also see the box, depending on how up-to-date your mobile or computer operating system is. I’ve added a thumbnail here which links to the image from my phone, so that readers can see how the text is intended to appear. If you are following along with this article by copying and pasting commands, feel free to exclude the lines with a box character if you’d prefer. The examples still work without those lines.

Note: since Arabic Unicode characters have the “right-to-left” attribute set, these words are rendered right-to-left in DBeaver on my Mac.
Well let me tell you: linguistics is hard work. After a month I’ve made a lot of progress. However, my Machine Learning jobs are now using lots of resources on the database server and it slows down my ad-hoc SQL analysis a lot. Separately, I have a growing concern about making extra sure we don’t lose all the work I’ve done so far.
After some discussion we realize the obvious answer is to create a hot standby. This is an extra copy of the database on a separate server which receives a stream of changes from the current database so that it’s always up-to-date. Furthermore, I can open a read-only connection to this hot standby to run my analysis queries. A perfect solution!
You get right to work – again using Ubuntu LTS and PostgreSQL version 15.
aws ec2 run-instances --key-name mac --instance-type t2.micro --tag-specifications 'ResourceType=instance,Tags=[{Key=Name,Value=research-db-hotstandby}]' --image-id ami-0fd2c44049dd805b8 --region us-east-1
sudo apt install postgresql-common
sudo sh /usr/share/postgresql-common/pgdg/apt.postgresql.org.sh
sudo apt install postgresql-15
# cut and paste instructions from https://ubuntu.com/server/docs/databases-postgresql to easily set up the hot standby databaseIn no time at all, I’m creating a new connection in DBeaver and running my analysis SQL on the new hot standby.
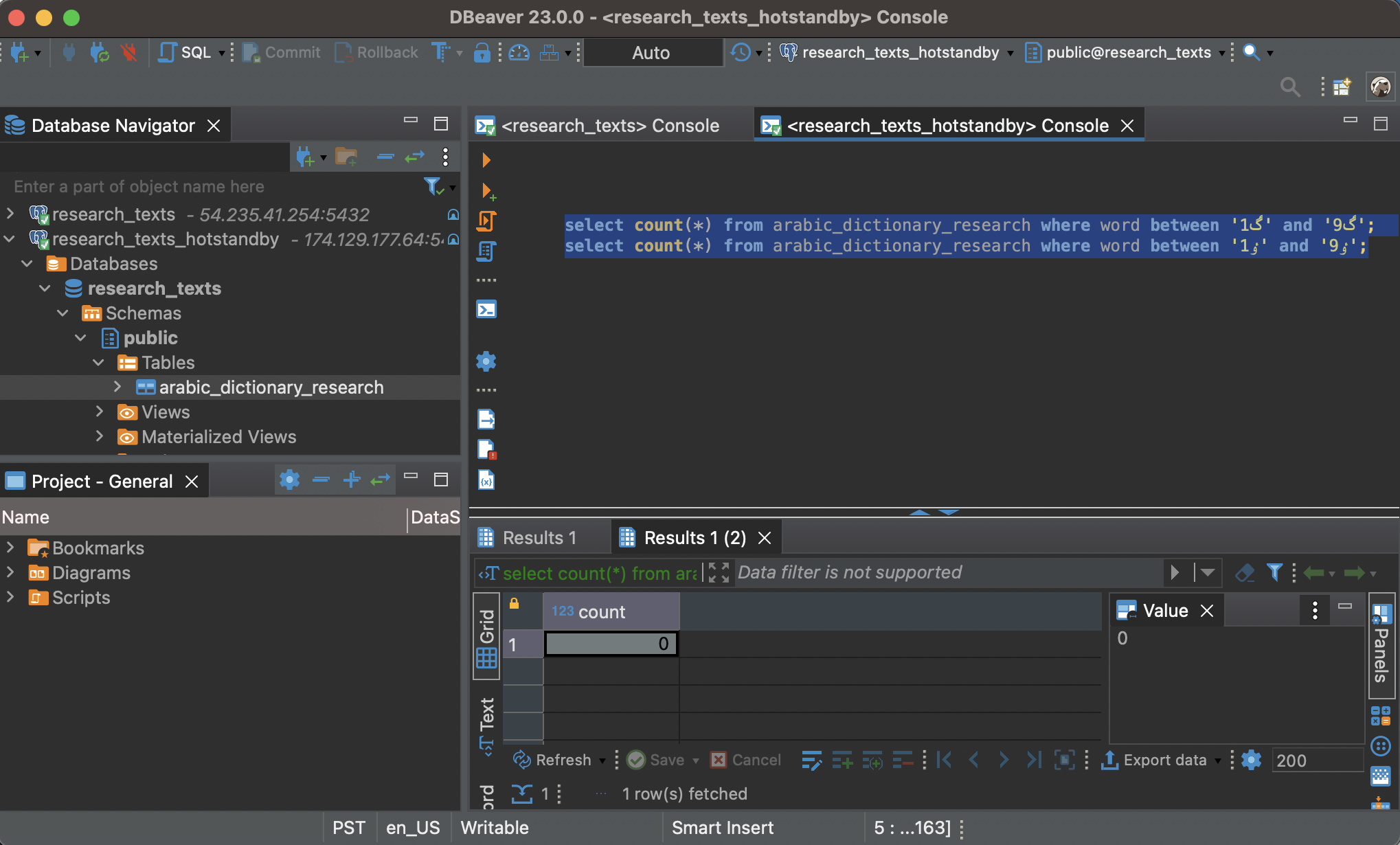
At first everything is great. My queries are running much faster now. But after a little while I run into my first problem. I am retrieving the cross references for a word that begins with the arabic letter Graf (code point U+08C8) but no record is returned by the database. I check a few more words and I’m horrified to discover that the Postgres hot standby seems to have lost a huge amount of my data.
select count(*) from arabic_dictionary_research where word between 'ࣈ1' and 'ࣈ9';
-- zero records found, we lost at least 890 records!
select count(*) from arabic_dictionary_research where word between 'ٶ1' and 'ٶ9';
-- zero records found, we lost at least 890 more records!Except for one thing: when I run the same queries over on the main read-write server, everything looks fine. The servers give different results. We immediately stop using the hot standby server… and I feel relieved that we hadn’t performed a failover or somehow lost the main server.
Note: You can try this for yourself by running the commands above. You’ll replicate the missing data on the hot standby, and the different results on different servers.
Diagnosis
So what happened? The root cause was the operating system we used for the hot standby.
===== PRIMARY DATABASE "research-db" =====
ami-0172070f66a8ebe63 (us-east-1)
ubuntu@ip-10-0-0-210:~$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 20.04.5 LTS
Release: 20.04
Codename: focal
===== HOT STANDBY DATABASE "research-db-hotstandby" =====
ami-0fd2c44049dd805b8 (us-east-1)
ubuntu@ip-10-0-0-117:~$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 22.04.2 LTS
Release: 22.04
Codename: jammyAnd while no messages were ever actively displayed to either the admin who created the hot standby or the researcher who was running SQL in DBeaver, there was a warning message buried in the database log on the hot standby server:
ubuntu@ip-10-0-0-117:~$ tail /var/log/postgresql/postgresql-15-main.log
2023-03-26 07:39:47.656 UTC [5053] LOG: restartpoint complete: wrote 71 buffers (0.4%); 0 WAL file(s) added, 0 removed, 0 recycled; write=7.026 s, sync=0.004 s, total=7.039 s; sync files=51, longest=0.003 s, average=0.001 s; distance=266 kB, estimate=14772 kB
2023-03-26 07:39:47.656 UTC [5053] LOG: recovery restart point at 0/3042B20
2023-03-26 07:39:47.656 UTC [5053] DETAIL: Last completed transaction was at log time 2023-03-26 07:36:32.138932+00.
2023-03-26 07:44:55.770 UTC [5053] LOG: restartpoint starting: time
2023-03-26 07:45:09.811 UTC [5053] LOG: restartpoint complete: wrote 141 buffers (0.9%); 0 WAL file(s) added, 0 removed, 0 recycled; write=14.031 s, sync=0.003 s, total=14.042 s; sync files=22, longest=0.002 s, average=0.001 s; distance=1309 kB, estimate=13425 kB
2023-03-26 07:45:09.811 UTC [5053] LOG: recovery restart point at 0/3189F90
2023-03-26 07:45:09.811 UTC [5053] DETAIL: Last completed transaction was at log time 2023-03-26 07:41:50.782267+00.
2023-03-26 09:20:06.353 UTC [5498] ubuntu@research_texts WARNING: database "research_texts" has a collation version mismatch
2023-03-26 09:20:06.353 UTC [5498] ubuntu@research_texts DETAIL: The database was created using collation version 153.14, but the operating system provides version 153.112.
2023-03-26 09:20:06.353 UTC [5498] ubuntu@research_texts HINT: Rebuild all objects in this database that use the default collation and run ALTER DATABASE research_texts REFRESH COLLATION VERSION, or build PostgreSQL with the right library version.Collation.
A topic that has been discussed quite a bit over the past few years among the PostgreSQL development community.
“Collation” basically means “putting words in the right order”. In programming terms, you can think of it as sorting strings – usually by following the rules of local languages. As such, it falls under the broad computer science category of internationalization and localization. The basic problem for PostgreSQL is that unlike most other mature relational databases, PostgreSQL does not lock down collation versioning in its own code & build process. Instead, PostgreSQL out-sources management of collation versioning (via either the GNU C Library or the International Components for Unicode) to the operating system administrator – who manages these libraries as part of the operating system, separately from the database software itself. When these external libraries are upgraded, their ordering rules change. That introduces inconsistency between the new ordering and what’s on disk. While rare in practice (so far), in the worst cases this has caused all kinds of failures like wrong query results, duplicate data violating unique constraints, and even unavailability due to WAL replay failure during crash recovery. A lot of quality articles have already been written, delving into this challenge that PostgreSQL is facing. I’ve listed some of my favorite starting points in the “Related Reading” section at the bottom of this article.
Lets review a few things about this particular example:
- This is using ICU (not the GNU C Library)
- This is using partitions (can’t fix this with an index rebuild; needs a full dump/load of the table)
- This is a hot standby (can’t fix it anyway, because primary read-write server still uses the other version of ICU)
- This is using the en-US locale for sort ordering (the most common default)
- No warning or problem indication of any kind was displayed to a user or operator. Software was installed, hot standby configured and started, with no visible warnings to the admin. In DBeaver, a connection was made and queries ran and wrong results were returned (missing data). The user saw nothing indicating any concern. We only looked for problems because the user knew that the results of one particular query were wrong.
On a side note, be wary of the ALTER ... REFRESH COLLATION VERSION commands that are suggested. It’s very important to understand that this does not fix any inconsistencies between persisted data and collation libraries – all it does is instruct PostgreSQL to make the error message go away indefinitely without changing anything. It’s assumed that you’ve manually fixed any problems yourself, and that you’re 100% sure you’ve verified there isn’t any problematic data remaining.
Operating systems need to be upgraded over time. A database with a smart phone app in front of it can end up storing any unicode character typed on the phone. Smart phones can switch their keyboards to support any local language. If you have a couple users originally from northern Pakistan who enter their names or addresses from their phones with Balti characters, then you might only have three safe options when it comes time to upgrade your operating system:
- Dump and load the full database (which will be a long downtime window if your database is large)
- Use logical replication with dump & load to reduce downtime (which is a very expensive project and far more time-consuming for your staff than dump-and-load)
- Find someone to build your old version of ICU on each new release of your operating system
It will be interesting to see how this plays out. There are so many operating systems where PostgreSQL runs: Linuxes, BSDs, Windows, Mac, etc. Each has its own matrix of ICU versions shipped with major OS versions. How many different old versions of ICU will be maintained on each operating system and distribution? Who will do the work?
ICU has dependencies on programming language features that need compiler support. Last month, ICU maintainers started a discussion about moving ICU to C++17 (it has required C++11 since v59 in 2017). What if you have the reverse problem of this discussion, where your future operating system compiler has difficulty with your old version of ICU? What if a future new compiler optimization technique or a change of default compilation options somehow impacted ordering? I think this is unlikely to be an issue anytime soon and wouldn’t be insurmountable, but things probably won’t be maintenance-free either.
String comparisons are used in a lot of places by the database. Besides indexes (of all kinds) and partitions and constraints, what else is impacted that we haven’t thought of yet? How about something like joins across FDWs – do they assume rows come back in sorted order? What about extensions like PostGIS and Timescale and others – do they have their own datatypes or storage formats that involve string comparisons?
But Surely, Sort Order Changes Are Uncommon, Right?
Nobody is about to change the order of the english alphabet. The Balti example above involves a new unicode character that was added in Unicode in version 14.0 (2021) to support translation work (it’s probably not common in names or addresses), and a fix to sort order for alif, wow and yah only with a high hamza (my Arabic is rusty; I’m not 100% sure but I think it was CLDR-11112 [String start with letter alif (ا) should not be indexed under hamza (ء) when using both locale ur and ar]).
But sort order changes are probably more common than you think.
- New characters (including emojis) are continually added to Unicode. Those characters can be entered into your existing database. The existing database accepts the code point and sorts with default rules for the unassigned code point. When you upgrade your collation library next year, you’ll get the “correct” sort order for that new code point.
- Incorrect sorting rules are corrected. For example: CLDR-9895 [Collation rules improvement for Tibetan] and CLDR-9748 [Update Kurdish (ku) seed collation]
- Unclear rules are clarified by governments, universities, or others. For example: CLDR-1035 [Collation rules for sv: now to separate v and w at first level] and CLDR-7088 [Swedish collation] and CLDR-2905 [Drop backwards-secondary sorting from French collation]
- Maintainers and developers make general improvements. For example: CLDR-15603 [Align Swedish (sv) collation naming with other (non-zh) languages] and CLDR-15910 [Inclusion of COLON in word break MidLetter class should be moved to tailoring for fi,sv]
- My favorite… code changes entirely unrelated to official language rules which change the way some “equal” strings are compared. In 2014, a 300-line commit to the GNU C Library refactored an internal cache for performance reasons and it changed string comparison results for at least 22,743 code points (largely CJK characters). This is not the infamous glibc 2.28 change – this was before that, back in Ubuntu 15.04.
Show Me The Data
In order to get a sense of how common these changes are, I came up with a test.
You might think that all you need to do is make a list of the characters and sort it – but unfortunately it’s more complicated than that. Humans have a knack for coming up with complicated rules about their languages. Do you remember your college writing class?! Accurate linguistic sort algorithms capture all of those rules by looking at groups of glyphs, not individual glyphs. And there are even cases where multiple code points together (a base and modifiers) make a single glyph. (On a related note, your language’s “string-length” functions might not be telling you what you think they are telling you…) Between glibc 2.26 and glibc 2.27 the characters Ò (U+D3) and Ô (U+D4) and Õ (U+D5) and Ö (U+D6) did not change their order relative to any other individual characters. But strings combining one of those characters with the letter “O” did change relative to other strings.
The test that I’ve come up with involves taking each Unicode code point and plugging it into a list of 91 patterns. This is not comprehensive but I think it gives some coverage. Unicode version 15 has 286,654 valid code points, not including control or surrogate code points. That results in a list of about 26 million strings. I wrote some bash and perl and SQL code to mostly automate the process of creating & sorting this list of 26 million strings across 10 years of historical versions of Ubuntu and RHEL. I tested glibc versions on both operating systems and I tested ICU versions on Ubuntu.
For glibc I performed a sort in en-US which catches changes to default sorting, and then I directly compared the Operating System locale data files between versions to find the remaining changes. For ICU, I only did the sort – however I tested the sort in seven different locales: en-US, ja-JP, zh-Hans-CN, ru-RU, fr-FR, de-DE, and es-ES. English, French, German and Spanish have identical counts. Chinese, Japanese and Russian seem to have some very small differences from the others.
Finally, I generated a table summarizing the results with links for drill-down into the data. This is published on GitHub. The column labeled “Total” tells the number of unicode blocks impacted by any changes and you can click it to see a summary. For each impacted unicode block, the summary tells which patterns appeared in the “diff” output for this operating system version and how many distinct code points appeared for that pattern and block. The column labeled “Blocks” tells the total number of distinct code points impacted. Clicking on that will open a list of each string that appeared in the diff, along with the pattern number and code point. For any given version of glibc or ICU this will tell you every individual code point that appeared in the “diff” of two sorted lists. Finally, the link labeled “Full Diff” is just what it says – the direct output of “diff” between the old sorted list of strings and the new sorted list of strings.
In summary: both glibc and ICU have regular collation changes. Both have had at least one release with very large numbers of changes.
You can see the summary table and drill-down data at https://github.com/ardentperf/glibc-unicode-sorting
Want to try it yourself? I did the ICU comparisons right inside PostgreSQL. The full list of strings is stored in a table and generated by a simple snippet of PL/pgSQL – you can copy the code and then try sorting this particular set of strings on as many locales and operating systems as you’d like, with both ICU and glibc. Just remember to remove the extra backslashes that are there for quoting, and replace the variable ${UNICODE_VERS} with the literal value 15 (or a different version if you want).

Related Reading
I have still only scratched the surface of collation and PostgreSQL. Work continues and there is a lot of additional great material to read, if you’re interested in getting into the weeds. Here are a few starting points:
- The official PostgreSQL wiki page for collations is the best starting point. It’s concise and brief and it already summarizes everything I’ve mentioned in this article. https://wiki.postgresql.org/wiki/Collations
- Just two weeks ago, Peter Eisenstraut published an article about how collation works. I think it’s one of the best articles I’ve read so far on this topic. http://peter.eisentraut.org/blog/2023/03/14/how-collation-works
- About two years ago, Thomas Munro published an article on the Azure database blog about index corruption from collation changes. Another one of my favorites that stands the test of time – especially since Thomas includes so many great links back into the official Unicode specs as he explains things. https://techcommunity.microsoft.com/t5/azure-database-for-postgresql/don-t-let-collation-versions-corrupt-your-postgresql-indexes/ba-p/1978394
- About a month ago, Jonathan Katz published an article on the AWS database blog about managing collation changes on RDS Open Source PostgreSQL and Aurora. This has a lot of useful SQL queries for people who are worried about impact from collation changes, and it has a little nugget tucked at the bottom about AWS freezing their glibc collation behavior at version 2.26-59 – which is pretty remarkable. https://aws.amazon.com/blogs/database/manage-collation-changes-in-postgresql-on-amazon-aurora-and-amazon-rds/
- Collation was discussed at the FOSDEM 2023 PGDay Developers Meeting and the notes are online. Joe Conway talked about some work that he’s done. There are some interesting tidbits here. https://wiki.postgresql.org/wiki/FOSDEM/PGDay_2023_Developer_Meeting#ICU_.2F_Collations
- Jeff Davis has been very involved with recent contributions around ICU and PostgreSQL, including a finding about ICU 55 that’s very interesting alongside the test results of my GitHub scripts on this version [pgsql-hackers mailing list thread “ICU 54 and earlier are too dangerous”]. https://www.postgresql.org/search/?m=1&q=davis+icu&l=1&d=365&s=d and https://commitfest.postgresql.org/41/3956/
- If you want to heckle me sometime, you can point out that I literally spent a year and a half writing this. November 2021 was when I promised this article to Robert Haas in a comment over on his blog. Yeah… this took a LOT longer than it should have!! http://rhaas.blogspot.com/2021/11/collation-stability.html
Among PostgreSQL installations globally, the problems we’re talking about here are serious but in practice they have occurred very rarely (so far). The largest risk is people who self-manage their databases and use libc linguistic collation and upgrade to RHEL 8 or Ubuntu 20.04 LTS or Ubuntu 18.10 non-LTS or Debian 10 without doing a dump & load; those OS upgrades include the glibc 2.28 changes. Of course C/POSIX/ucs_basic and ICU collation are not impacted by this. Enormous progress has been made. But some hard questions aren’t answered yet and the PostgreSQL community still has work to do.
Nonetheless, one thing you can’t help noticing is the ongoing investment and open collaboration of very smart engineers across multiple companies and geographies. This is open source at its best, and it’s one of the reasons that I know PostgreSQL is here to stay.




Discussion
Trackbacks/Pingbacks
Pingback: Default Sort Order in Db2, SQL Server, Oracle & Postgres 17 | Ardent Performance Computing - May 22, 2024