
TLDR: I was starting to think that the best choice of default DB collation (for sort order, comparison, etc) in Postgres might be ICU. But after spending some time reviewing the landscape, I now think that code-point order is the best default DB collation – mirroring Db2 and Oracle – and linguistic sorting can be used via SQL when it’s actually needed for the application logic. In existing versions of Postgres, this would be something like C or C.UTF-8 and Postgres 17 will add the builtin collation provider (more details at the bottom of this article). This ensures that the system catalogs always use code-point collation, and it is a similar conclusion to what Daniel Vérité seems to propose in his March 13 blog, “Using binary-sorted indexes”. I like the suggestion he closed his blog with: SELECT ... FROM ... ORDER BY colname COLLATE "unicode" – when you need natural language sort order.
I spent some time reading documentation, experimenting, and talking to others in order to learn more about the general landscape of collation and SQL databases. It’s safe to say that every SQL database that’s been around for more than a hot minute has 🍿 fun collation quirks. (Another reason you shouldn’t write your own database… rediscovering all of this for yourself.)
Next week at PGConf.dev in Vancouver, Jeff Davis (and I) will be talking about collation and Postgres. If you’ll be at the conference then be sure to stop by and listen!
Wednesday May 29 at 2:30pm in the Canfor room (1600) – “Collations from A to Z” – https://www.pgevents.ca/events/pgconfdev2024/schedule/session/95-collations-from-a-to-z/
Db2
I asked Josh Tiefenbach – a friend who previously worked in Db2 development – and he’s helped me better understand the picture here. First off: Db2 will format your dates and numbers according to the client’s localization environment. I heard a funny story about an IBM engineer whose programs were randomly breaking because of comparison mismatches on dates. It wasn’t critical enough to warrant an immediate deep dive, and after a few months of annoyance they realized it was because their laptop was set to canadian english while some other systems were set to american english, and the client locale information would be passed to the database and change the string output format.
However, while date formatting can be influenced by client locale, SQL statements with ORDER BY will always sort your results according to server settings. If your server is in switzerland, I don’t think you can have one terminal or client in france automatically ordering strings with french rules and another terminal in germany automatically ordering strings with german rules. You can write explicit SQL syntax to accomplish this (and use different SQL statements in france and germany), you just can’t do it with an implicit client locale setting. Finally: if I understand correctly, today new Db2 installations default to unicode encoding with code-point order collation which is called IDENTITY in Db2 nomenclature.
- A good entry point to Db2 docs on collation is https://www.ibm.com/docs/en/db2/11.5?topic=collation-collating-sequences
- Docs for CREATE DATABASE sql and Create-database api
- It looks to me like in some cases, Db2 can automatically set up a database to maintain compatible sort order with an older territory that is configured at the client when creating the database. In this case, only code points that directly map to the old code page are linguistically sorted, and all other code points get IDENTITY collation. (🍿 Fun Collation Quirk) https://www.ibm.com/docs/en/db2/11.5?topic=collation-language-aware-collations-unicode-data and https://www.ibm.com/docs/en/db2/11.5?topic=support-supported-territory-codes-code-pages
- UCA (Unicode Collation Algorithm, same as ICU) is not default but can be configured in Db2. It looks like IBM “deprecated” Unicode 4.0 however as of Db2 v11.5 there are still four versions of UCA built into the database: Unicode 4.0 (CLDR 1.2), Unicode 5.0 (CLDR 1.5.1), Unicode 5.2 (CLDR 1.8.1) and Unicode 7.0 (CLDR 2.7.0.1). It’s pretty hard to deprecate a collation in the database world. https://www.ibm.com/docs/en/db2/11.5?topic=collation-unicode-algorithm-based-collations
- For unicode databases, system catalogs always use IDENTITY (code-point order) collation, even when the database default is linguistic collation.
- After the database is created, the default collation cannot be changed.
SQL Server
I did some searching to figure out what SQL Server does. My best read is that – still today – SQL Server defaults to 8-bit encodings (like Windows-1252) and an associated ISO-8859-ish collation based on what language you picked for your Windows Server install.
They’ve supported UTF-16 in the database forever via the NVARCHAR data type. (Mandatory 2x storage overhead… 🍿 Fun Encoding Quirk) An option for UTF-8 encoding was added around 2019 but it seems to me this is not widely used.
I asked Brent Ozar if he had any insights he could share around this. Brent confirmed that the vast majority of SQL Servers use default collation. And this leads often to an interesting challenge:
- You’ve got a database that was created on another server, with a different default collation, and the database inherited that
- You create temp tables without specifying collation (so they inherit the server’s default collation)
- You load data from the user database into the temp table
- You join the user table & temp tables together on a column, and that column has two different collations (one in the temp table, one in the user db) and you get errors
Because that’s been a widely known issue for decades, the practical solution is pretty simple: when vendors hand out databases to their clients, like for packaged applications, they just say as part of the requirements, “Your SQL Server has to use ____ collation,” and they give installation instructions for when the user’s setting up their SQL Server. OR, the vendor learns the problem early on, and stops joining on strings, and uses numbers for pk/fk fields instead. (🍿 Fun Collation Quirk)
Thank you Brent for this!
- A good entry point to SQL Server docs on collation is https://learn.microsoft.com/en-us/sql/relational-databases/collations/collation-and-unicode-support?view=sql-server-ver16
- The best explanation I found of SQL Server was Solomon Rutzky’s Stackoverflow answer at https://stackoverflow.com/questions/5182164/sql-server-default-character-encoding
- An interesting deep-dive on what exactly these ISO-8859-ish collations are is at https://sqlquantumleap.com/2021/05/21/sql-server-collations-what-does-cp1-mean-in-sql_latin1_general_cp1_ci_as/ (and this is why I say “ish” … 🍿 Fun Collation Quirk)
- Collation cannot be changed for a server, however it can be changed for a database (make sure to read the doc page on data conversion with collation changes).
- From my read of the Azure SQL Database docs, it seems like that version might allow control of system catalog collation (separate from database collation). I don’t see the
CATALOG_COLLATIONclause ofCREATE DATABASEin the docs for SQL Server 2022 (windows or linux). On those installations this is likely controlled by the Server Collation (which is separate from the Database Collation).
Oracle
I myself have an Oracle background, so I had the joy of discovering Oracle’s rather noticeable idiosyncrasies here.
Oracle takes a fundamentally different approach to default collation: it is a property of the client connection rather than a property of the server. Similar to Db2, Oracle defaults to unicode encoding and code-point order collation which is called BINARY in Oracle nomenclature …UNLESS you live in Europe, the Middle East, Quebec, or a few other unlucky countries. China and Japan and Korea and India – lucky. Thailand and Vietnam and Pakistan – unlucky. (I have no idea what reasoning was behind this seemingly arbitrary list!)
It gets fun in the unlucky countries. If your client environment is set to one of these languages, then by default Oracle makes ORDER-BY and a few functions (like regex) sort words with a collation reflecting your client locale. But operators like greater-than and less-than, group-by, and indexes all still use code-point order (BINARY) collation.
As a result, this is the default behavior of Oracle in “unlucky” countries:
NLS_LANG=french_france.al32utf8 sqlplus / as sysdba
SQL> select * from test_table order by field1;
FIELD1
--------------------------------------------------
baño
banqueta
Baptisto
chorizo
como
SQL> select * from test_table where field1 <= 'banqueta' order by field1;
FIELD1
--------------------------------------------------
banqueta
Baptisto(🍿 Fun Collation Quirk)
Sometimes I wonder how the rest of the world can live with us Americans. Part of me thinks a bunch of them probably run Oracle with NLS_LANG=AMERICAN out of exasperation (and conditioning). One long-time Oracle person suggested that in the days before databases were relational, one might have looked at this behavior through the lens of “projection” versus “presentation” layers? 🤔
But on the plus side, Oracle seems to be the most flexible with collation, it being a property of the client connection rather than the server. By simply changing your client environment or setting a session variable, you can switch to all-binary mode (NLS_SORT setting), or switch to all-linguistic mode (NLS_COMP setting – perf caveats notwithstanding, eg. need to create linguistic indexes).
All-binary mode is straightforward, and is default for many languages (including “ENGLISH” and the default value of “AMERICAN” – which I assume is named this way because Americans don’t speak proper English 😂). But evidently users have hit a few strange bugs in all-linguistic mode and found themselves waiting for Oracle to create one-off patches.
Oracle has published a detailed support note 227335.1 about Linguistic Sorting, including a list of known bugs and an explicit recommendation against setting linguistic sorting at the database/instance level.
“This is actually a rather bad idea, linguistic sorting is much more cpu consuming than the binary sorting (and needs linguistic indexes) hence it should be set (by using alter session for example) by the application and only when actually needed for the application logic (and the tables involved have linguistic indexes defined).”
— support note 227335.1 —
And similar to SQL Server, at the end of the day the vendors of packaged applications are often going to dictate how the database is configured. Let’s just take one simple example: Oracle eBusiness Suite.
Support doc 396009.1 includes these four mandatory Database Initialization Parameters for E-Business Suite Release 12:
# Mandatory parameters are denoted with the #MP symbol as a
# comment. This includes parameters such as NLS and optimizer
# related parameters.
nls_comp = binary #MP
nls_sort = binary #MP
nls_date_format = DD-MON-RR #MP
nls_length_semantics = BYTE #MPIf using Oracle Applications in global organizations, you would refer to support doc 393861.1 for more details. Oracle Apps releases starting with 12.2.2 (2013) support linguistic sort order. And how is it implemented? The NLS_SORT session variable is set by the application – not set at the database level. And NLS_COMP is still required to be in BINARY mode (WHERE clause, “=”, like etc).
(🍿 Fun Collation Quirk)
It’s worth mentioning that in Oracle you can also write explicit SQL syntax to specify a collation, you can bind a collation to data, and you can define default collation at multiple levels. But interestingly, Postgres added support for data-bound collation about 5-6 years before Oracle! (PG 9.1 in 2011 versus Oracle 12.2 in 2016/2017)
- A good entry point to Oracle docs on collation is https://docs.oracle.com/en/database/oracle/oracle-database/23/nlspg/linguistic-sorting-and-matching.html#GUID-84F2A594-E641-4436-A903-D5D5B4D7FFA9
- It’s worth noting that like Db2 and SQL Server and Postgres, Oracle also supports single-byte encodings and associated collations that predate Unicode. Details can be found in the documentation.
- The “BINARY” column of table 5-3 contains the complete list of SQL syntax & functions, showing which ones default to BINARY collation and which ones default to linguistic collation (NLS_SORT) when you’re in an “unlucky” locale. https://docs.oracle.com/en/database/oracle/oracle-database/19/nlspg/linguistic-sorting-and-matching.html#GUID-85328A92-CB08-4467-9F02-42E9EF9D41B7__CIHBFIID Summary – linguistic collation is used for ORDER BY, Analytic Functions, REGEXP_* functions and NLS* functions. Binary collation is used for GROUP BY, LIKE & IN & BETWEEN, operators like < > =, UNION & INTERSECT & MINUS, and much more.)
- The “Default Sort” column of Table A-1 shows exactly which lucky locales default to BINARY sorting for ORDER-BY and which unlucky locales default to a linguistic sort for ORDER-BY (but not other operators – see previous bullet point) https://docs.oracle.com/en/database/oracle/oracle-database/23/nlspg/appendix-A-locale-data.html#GUID-D2FCFD55-EDC3-473F-9832-AAB564457830
- That default sort column was first added to the Oracle Globalization manual in version 10.1 (2003) however all the way back to v8.1.6 (late 90’s) I see the default value of NLS_SORT is “Default character sort sequence for a particular language” …I didn’t check older docs but it sounds to me like this behavior has existed for a very long time in Oracle. I guess after 30-40 years, why change now?
- Per support note 227335.1 – even when Oracle is in all-linguistic mode (NLS_COMP=LINGUISTIC), indexes are still created as BINARY by default (you need explicit SQL syntax to create linguistic indexes), and I suspect the catalog always works in BINARY mode under the covers.
- UCA (Unicode Collation Algorithm, same as ICU) is not default but can be configured in Oracle. It looks like Oracle “deprecated” Unicode 6.1 in 21c however as of today there are still four versions of UCA built into the database: Unicode 6.1, Unicode 6.2, Unicode 7.0 and Unicode 12.1. It’s pretty hard to deprecate a collation in the database world.
- The database does not have a default collation. The default collation of a table can be changed, but this only impacts newly added columns – existing columns are not changed. A client can change the locale settings it uses to connect at any time, but this may impact performance (eg. indexes may not be used).
Postgres
Historically, Postgres has relied on external libraries for collation (originally the operating system libc, with the later addition of an option to use ICU from unicode.org if it’s separately installed on the system). This external dependency is unlike every other relational database that exists.‡ This means that the onus is on the administrators who install and manage software to not mess up their database by changing external libraries in a way that breaks things. When you install the next major version of RHEL, if you physically detach/attach your storage volume with 10TB of datafiles to avoid spending two weeks on a logical dump-and-load, then it’s your job to go find the old version of ICU and get it compiled, installed, and working on your new server. Let’s hope you’re not using linguistic collation from the OS libc (like en-US). Code-point order collation is a fine choice though.
‡Interestingly, Postgres does historically have a built-in collation called “C” however it’s not used by default and it has some usability issues in non-english languages. For example, accented characters and other non-ASCII characters don’t work with upper/lower, regex, etc
As I mentioned above, Postgres 17 will most likely include a builtin stable collation which is very performant and fast, comparing characters by code point and addressing problems with the older “C” collation. (Hooray! Scroll Down for More Details!) But even in version 17, Postgres defaults to the locale settings from the OS environment (eg. LANG/LC_COLLATE) when the initdb program creates a new database cluster. https://www.postgresql.org/docs/current/app-initdb.html
In practice, this means that – similar to SQL Server – Postgres defaults are determined by Operating System defaults. I remember running linux installers and choosing locales many times over the years. These days it’s just as common to use a virtual machine image. I pulled up a few official versions of Ubuntu on EC2 to see what the defaults looked like, and I got different results!
| Operating System | Default LANG (locale) | Collation of default database | PostgreSQL Version | AMI |
| Ubuntu 16.04.7 LTS | LANG = en_US.UTF-8 | en_US.UTF-8 | apt install postgresql-9.5 | ami-0b0ea68c435eb488d |
| Ubuntu 18.04.6 LTS | LANG = C.UTF-8 | C.UTF-8 | apt install postgresql-10 | ami-0279c3b3186e54acd |
| Ubuntu 20.04.3 LTS | LANG = C.UTF-8 | C.UTF-8 | apt install postgresql-16 | ami-083654bd07b5da81d |
| Ubuntu 22.04 LTS | LANG = C.UTF-8 | C.UTF-8 | apt install postgresql-16 | ami-0ba8e031ca32ab37f |
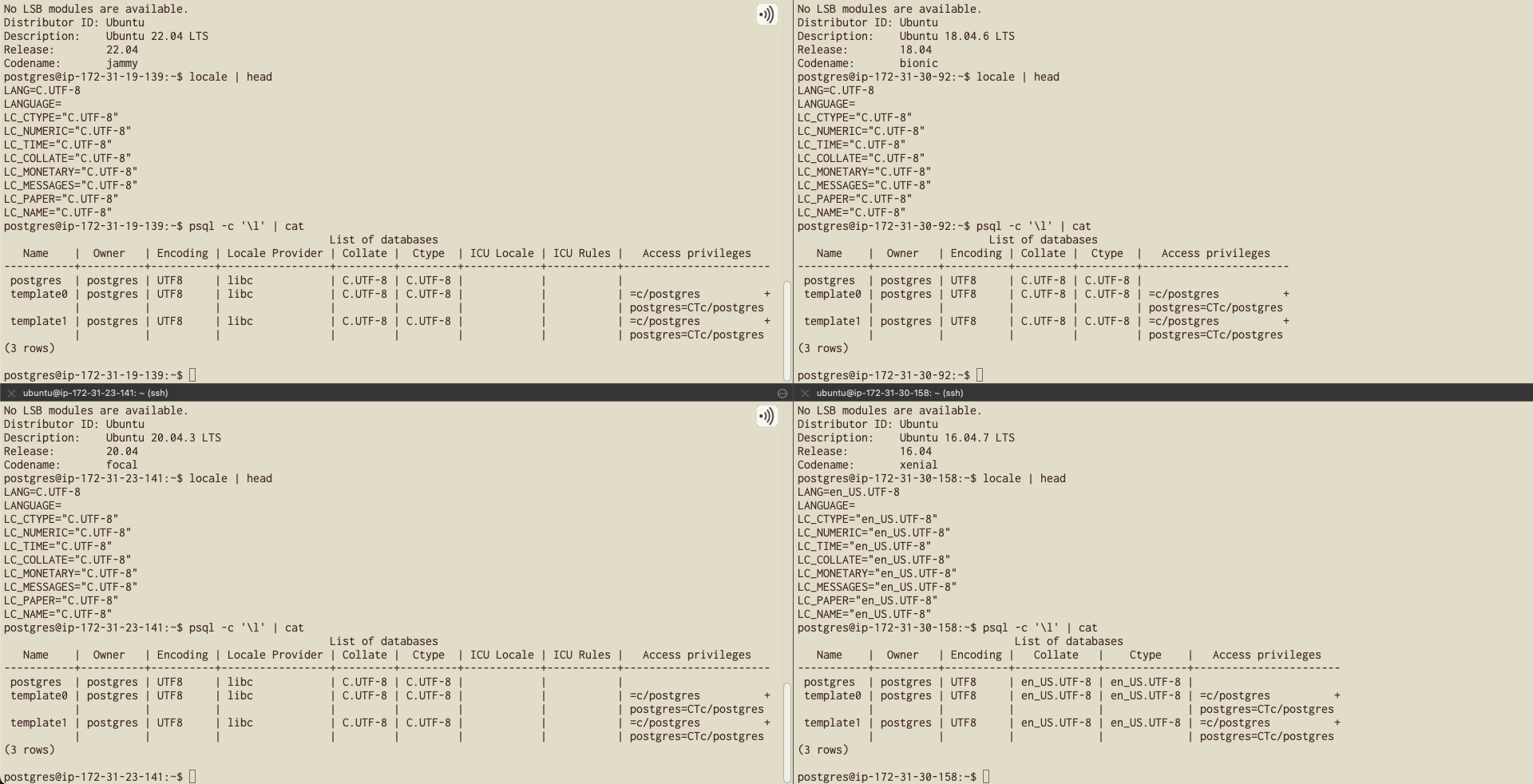
So it turns out that a number of Postgres installations already use libc C.UTF-8 collation by default, which is a safer choice than a libc linguistic collation like en_US.UTF-8.
- A good entry point to Postgres docs on collation is https://www.postgresql.org/docs/current/collation.html
- The official PostgreSQL wiki page for collations has some info from 2019-2021, but doesn’t have the latest updates yet (as of publishing date of this blog). https://wiki.postgresql.org/wiki/Collations
- Peter Eisenstraut’s blog is an amazing resource on collation in PostgreSQL. http://peter.eisentraut.org/
- Daniel Vérité’s blog also has several great articles about collation in PostgreSQL. https://postgresql.verite.pro/blog/
- About three and a half years ago, Thomas Munro published an article on the Azure database blog about index corruption from collation changes. Another one of my favorites that stands the test of time – especially since Thomas includes so many great links back into the official Unicode specs as he explains things. https://techcommunity.microsoft.com/t5/azure-database-for-postgresql/don-t-let-collation-versions-corrupt-your-postgresql-indexes/ba-p/1978394
- Related article here on my blog: Did Postgres Lose My Data?
- UCA (Unicode Collation Algorithm, via ICU) is not default but can be configured in Postgres. It needs to be installed separately by the administrator before it can be used by Postgres. It is the responsibility of administrators to ensure that the same version of ICU continues to be available if the database is physically migrated to new servers or operating systems, and that the same version of ICU is available on hot standbys. Even a small ICU update can be risky. Postgres docs say it works with ICU 4.2 (CLDR 1.7.1) and newer. However there was a mailing list thread suggesting that ICU 54 and earlier should be avoided.
- A Postgres client can detect encoding based on the client environment (LC_CTYPE for libpq) but – similar to Db2 – sort order is determined only by server settings and SQL syntax.
The Difference Between C and C.UTF-8 Collation in PostgreSQL – and Whats New in 17
In PostgreSQL, you first choose a provider (libc or icu) and then you choose a collation. The collation doesn’t just control ordering, it also controls character semantics (upper/lower/initcap, regex classes, equality, etc).
PostgreSQL has only two collations with code-point ordering: libc C collation and libc C.UTF-8 collation. Before Postgres 17, you have to choose between the good character semantics of C.UTF-8 collation and the performance and reliability of C collation. Thanks to Jeff Davis’s work, Postgres 17 will soon offer the best of both worlds via the new provider called “builtin” with C.UTF-8 collation (same collation name, different provider). The already-existing C collation (libc provider) can also be accessed through the new “builtin” provider, which makes sense because this collation was built into Postgres all along.
Builtin C.UTF-8 collation (aka pg_c_utf8) has the same blazing fast performance on sorts and comparisons as C collation. C collation might slightly edge out builtin C.UTF-8 performance on character semantics like uppercase/lowercase operations. But personally I’ll happily trade that for broadly useful character semantics and rock-solid reliability.
| libc & pg17 builtin provider C collation | libc provider C.UTF-8 collation | pg17 builtin provider C.UTF-8 collation |
| implemented internally; does not call libc (the PG provider name of “libc” is misleading) | calls libc | implemented internally; does not call libc |
| stable & safe; does not change | changes should be uncommon (less than icu and libc linguistic locales), but history shows that both character semantics and sort order have not remained unchanged for example in Debian/Ubuntu (cf. mailing list thread) | stable & safe; does not change |
| poor semantics for non-ASCII characters; eg. accented characters break upper/lower, regex, etc | good semantics for non-ASCII characters (upper/lower, regex, etc) implementation specifics can vary by operating system and libc version | good semantics for non-ASCII characters (upper/lower, regex, etc) same on all platforms: regex classes based on “POSIX Compatible” semantics spec, case mappings are “simple” variant |
| fast | slower than C and builtin, faster than libc linguistic and icu | fast ‡ |
| not default | default for some operating system installations, not default for others | not default |
‡builtin C.UTF-8 has the same performance as C for collation/sorting, but it is a little slower than C for character semantic operations like upper/lower, etc. It is faster than libc and ICU for character semantic operations.
As I said at the beginning – I now lean toward always setting the Postgres database default to code-point order collation (carefully considering the differences between C and C.UTF-8) and specifying linguistic sorting with SQL when it’s actually needed for the application logic. This approach is used for many existing enterprise applications & databases around the world today and it ensures that system catalogs use code-point collation. There are speed & performance benefits, and this provides the best stability and safety.
.
Final Notes:
- I probably know a little more about Postgres collation than the average Postgres user, but I haven’t kept up with all the mailing list threads. Folks like Jeff, Peter, Daniel, Thomas and many other PG hackers know WAY more than I do. It’s very possible I’ve made some mistakes here. Please let me know if you spot anything I got wrong!
- Lukas Fittl recently reviewed the new pg17 builtin collator in “5mins of Postgres” episode 107. Well worth the listen! https://pganalyze.com/blog/5mins-postgres-17-builtin-c-utf8-locale
- Just for fun… on a related note, but more about encodings than collations, this is a fun blog post. “Falsehoods Programmers Believe About Plain Text” https://jeremyhussell.blogspot.com/2017/11/falsehoods-programmers-believe-about.html




Discussion
No comments yet.